Un jeu de données ou data set est un ensemble ou une collection de données. Cet ensemble prend forme dans un tableau avec des lignes et des colonnes. Chaque colonne décrit une variable particulière. Et chaque ligne correspond à un élément donné de l’ensemble de données. Cela fait partie de la gestion des données.
Les ensembles de données décrivent les valeurs de chaque variable pour des quantités inconnues d’un objet ou des valeurs de nombres aléatoires. Les valeurs de cet ensemble sont appelées une donnée. L’ensemble de données se compose de données d’un ou plusieurs éléments correspondant à chaque ligne.
Les différents types de jeux de données
Dans les statistiques, il existe différents types de jeux de données publiés :
Jeu de données numériques : un ensemble de chiffres tels que le poids et la taille d’une personne, son âge, le taux de globule rouge dans son sang dans son rapport médical, etc.
Jeu de données bivariées : un ensemble de données qui a deux variables comme le rapport poids/puissance d’une voiture par exemple.
Jeu de données multivariées : un ensemble de données à plusieurs variables comme le volume des colis qui nécessite trois variables (longueur, largeur et hauteur).
Jeu de données catégorielles : un ensemble de données catégorielles qui représentent les caractéristiques d’une personne ou d’un objet.
Jeu de données de corrélation : un ensemble de données qui démontrent la corrélation entre plusieurs variables ou données par exemple.
Comment créer un jeu de données ?
Il existe différentes manières de créer des jeux de données . En effet, il existe plusieurs liens menant vers des sources contenant toutes sortes de jeux de données. Certains d’entre eux seront des données générées par des robots. D’autres sont produites par des outils de Business intelligence créés à partir de la Machine Learning. D’autres seront des données collectées via des enquêtes. Il existe également des jeux de données enregistrées à partir d’observations humaines ou extraites des sites Web et des API.
Avant de travailler sur un jeu de données, il est important de répondre aux questions suivantes :
D’où viennent les données ?
Comment cet ensemble de données est-il été créé ?
Il ne faut pas se lancer directement dans l’analyse. L’idéal est de prendre le temps de comprendre d’abord les données sur lesquelles travailler.
Les jeux de données publiques pour les projets de visualisation de données
Lorsqu’on recherche un bon jeu de données pour un projet de visualisation de données :
Bien ordonné pour ne pas avoir à passer beaucoup de temps à nettoyer les données.
Suffisamment nuancé et intéressant pour faire des graphiques.
Pas trop de lignes ou de colonnes pour simplifier le travail.
De nombreux sites d’actualités publient des données ouvertes ou open data. Ils sont d’excellents endroits où trouver de bons jeux de données pour des projets de visualisation de données. Ils respectent la politique de confidentialité des gens qui ont permis de générer ces données. Généralement, ils le nettoient et proposent des graphiques pouvant être reproduits ou améliorés.
Avec l’explosion des données clients, notamment des données personnelles, les entreprises cherchent des moyens d’obtenir des informations sur ce qui les entoure. Cela est fait dans le respect de la politique de confidentialité soutenue par le RGPD (règlement général sur la protection des données). Afin d’obtenir une perspective de leur activité sur le marché, elles ont recours à ce que beaucoup ont convenu d’appeler le data marketing : les moyens de connaître et de planifier des actions marketing à travers la mesure et le contrôle des données.
Qu’est-ce que le data marketing ?
Le data marketing est la mesure et l’analyse de toutes les sources d’informations disponibles, y compris sur les réseaux sociaux. Cette approche est ce qui est défini comme étant le data driven marketing. Les entreprises qui l’appliquent peuvent prendre des décisions qui influencent le contrôle et la définition d’une stratégie marketing et commerciale.
On peut dire que le data marketing n’est pas un type de marketing spécifique à l’instar du marketing entrant ou du marketing digital par les moteurs de recherche (SEO, SEM…). Bien que ces types de marketing coexistent, ils sont en grande partie séquentiels. Chacun d’eux fait partie de différentes parties de ce que l’on appelle l’entonnoir de vente marketing.
Les bases de données marketing couvrent tous les composants d’une stratégie marketing. Chacun des éléments d’un plan marketing doit pouvoir être mesurable. De par sa nature même, il est une pièce complémentaire à l’ensemble des actions marketing qu’une entreprise mène. Ainsi, il permet de connaître l’utilisation des données qui affectent l’ensemble de sa stratégie marketing, soutenant son activité passée et présente pour établir de nouvelles campagnes publicitaires.
Que faire des données ?
La chose fondamentale dans le data marketing est que les entreprises peuvent étudier les modèles de comportement, la tendance des utilisateurs et leurs habitudes. Une fois que tout cela a été détecté, elles ont la possibilité de définir clairement les actions à appliquer en marketing.
Pour ce faire, elles ont deux solutions. L’une est manuelle où elles évaluent et supervisent toutes les données avec leur équipe. L’autre est d’utiliser l’intelligence artificielle par le biais d’outils d’apprentissage automatique qui se charge de révéler le moment pour réaliser l’action de communication.
En remontant l’histoire d’au moins une dizaine d’années, les données fondamentales pour exercer le contrôle de l’information et la gestion des données ont commencé à être développées dans le marketing. Cela a permis d’avoir le contrôle de toutes les informations qui affectent une entreprise.
Des données importantes et volumineuses sont collectées par les entreprises à chaque seconde. Il est essentiel de les reconnaître, de les stocker, de les collecter, de les classer et de les exporter. Ces techniques doivent aller de pair pour faciliter la compréhension de tous les processus.
Comment appliquer le data marketing ?
Pour mettre en place le data marketing dans une stratégie marketing, toute entreprise doit connaître les points suivants :
Volume de données. Toutes les données nécessaires sont tirées du Big Data. Il est essentiel de détecter celles qui affectent ou non le business model.
Organisation et hiérarchie. Grâce à un diagramme de flux de travail marketing, on sélection les données. Puis, on les hiérarchise et les organise.
Accès rapide. Il faut disposer d’un processus pour pouvoir consulter immédiatement les données lorsque c’est nécessaire.
Plusieurs sources. Toute entreprise doit disposer de différentes sources de données du Big Data pour pouvoir les intégrer dans sa stratégie marketing.
Procédure de données. Il est important de connaître et de croiser toutes les variables. L’objectif est de pouvoir extraire les informations sans erreur.
Visualisation des données. Les informations doivent donner la possibilité de les représenter sous forme de graphiques ou d’images pour les rendre plus compréhensibles.
En appliquant toutes ces recommandations, une entreprise possède une valeur ajoutée précieuse pour la prise de décision dans sa stratégie marketing. Pour faire simple, il s’agit d’un modèle de gestion intelligent des données.
Quels sont les avantages du data marketing ?
Parmi les avantages, on peut citer les suivants :
Facilite la prise de décision.
Améliore la capacité stratégique d’une entreprise.
Améliore la mesure du risque et la capacité de gestion de l’entreprise.
Aide à comprendre l’entreprise et les clients.
Donne la possibilité de rechercher de nouvelles opportunités d’affaires.
Soutiens la réalisation des objectifs de l’entreprise.
Le convolutional neural network est une forme spéciale du réseau neuronal artificiel. Il comporte plusieurs couches de convolution et est très bien adapté à l’apprentissage automatique et aux applications avec Intelligence artificielle (IA) dans le domaine de la reconnaissance d’images et de la parole, de la vente et du marketing ciblé et bien plus encore.
Introduction au convolutional neural network
L’appellation convolutional neural network signifie « réseau neuronal convolutif » en Français. L’abréviation est CNN. Il s’agit d’une structure particulière d’un réseau de neurones artificiels spécialement conçu pour l’apprentissage automatique et le traitement d’images ou de données audio.
Dans une certaine mesure, son fonctionnement est calqué sur les processus biologiques derrières les réflexions du cerveau humain. La structure est similaire à celle du cortex visuel d’un cerveau. Le convolutional neural network se compose de plusieurs couches. La formation d’un réseau de neurones convolutifs se déroule généralement de manière supervisée. L’un des fondateurs du réseau de neurones convolutifs est Yann Le Cun.
Mise en place d’un convolutional neural network
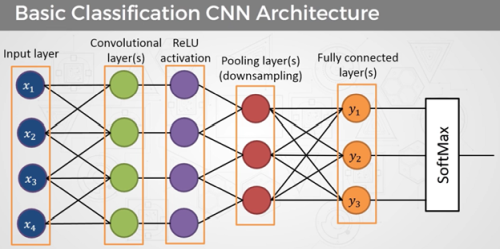
Des neurones selon une structure entièrement ou partiellement maillés à plusieurs niveaux composent les réseaux de neurones conventionnels. Ces structures atteignent leurs limites lors du traitement d’images, car il faudrait disposer d’un nombre d’entrées correspondant au nombre de pixels. Le nombre de couches et les connexions entre elles seraient énormes et ne seraient gérables que par des ordinateurs très puissants. Différentes couches composent un réseau neuronal convolutif. Son principe de base est un réseau neuronal à propagation avant ou feedforward neural network partiellement maillé.
Les couches individuelles de CNN sont :
Convolutional layers ou couches de convolution (CONV)
Pooling layers ou couches de Pooling (POOL)
ReLU layers ou couches d’activation ReLU (Rectified Linear Units)
Fully Connected layers ou couches Fully Connected (FC)
La couche de Pooling suit la couche de convolution et cette combinaison peut être présente plusieurs fois l’une derrière l’autre. La couche de Pooling et la couche de convolution étant des sous-réseaux maillés localement, le nombre de connexions dans ces couches reste limité et dans un cadre gérable, même avec de grandes quantités d’entrées. Une couche Fully Connected forme la fin de la structure.
Les tâches individuelles de chacune des couches
La couche de convolution est le plan de pliage réel. Elle est capable de reconnaître et d’extraire des caractéristiques individuelles dans les données d’entrée. Dans le traitement d’image, il peut s’agir de caractéristiques telles que des lignes, des bords ou certaines formes. Les données d’entrée sont traitées sous la forme d’une matrice. Pour ce faire, on utilise des matrices d’une taille définie (largeur x hauteur x canaux).
La couche de Pooling se condense et réduit la résolution des entités reconnues. À cette fin, elle utilise des méthodes telles que la mise en commun maximale ou la mise en commun de la valeur moyenne. La mise en commun élimine les informations inutiles et réduit la quantité de données. Cela ne réduit pas les performances du Machine Learning. Au contraire, la vitesse de calcul augmente en raison du volume de données réduit.
La couche d’activation ReLU permet un entraînement plus rapide et plus efficace en définissant les valeurs négatives sur zéro et en conservant les valeurs positives. Seules les fonctionnalités activées passent à la couche suivante.
La couche Fully Connected forme la fin d’un convolutional neural network CNN. Elle rejoint les séquences répétées des couches de convolution et de Pooling. Toutes les caractéristiques et tous les éléments des couches en amont sont liés à chaque caractéristique de sortie. Les neurones entièrement connectés peuvent être disposés dans plusieurs plans. Le nombre de neurones dépend des classes ou des objets que le réseau de neurones doit distinguer.
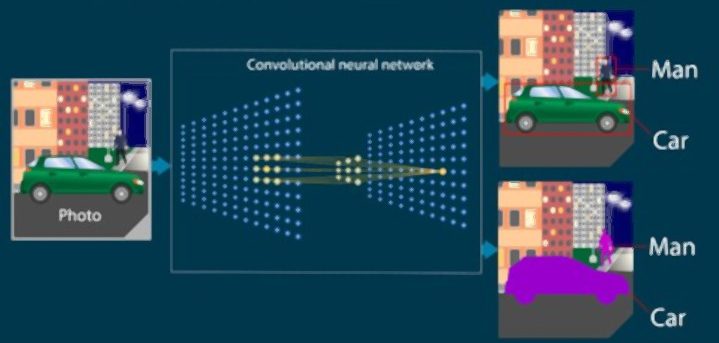
La méthode de travail à l’exemple de la reconnaissance d’image
Un CNN peut avoir des dizaines ou des centaines de couches qui apprennent à détecter différentes caractéristiques d’une image. Les filtres sont appliqués à chaque image d’apprentissage à différentes résolutions. La sortie de chaque image alambiquée est utilisée comme entrée pour la couche suivante. Les filtres peuvent aller de caractéristiques très simples telles que la luminosité et les contours à des caractéristiques plus complexes comme des spécificités qui définissent l’objet de manière unique.
Fonctionnalités d’apprentissage
Comme d’autres réseaux de neurones, une couche d’entrée, d’une couche de sortie et de nombreuses couches intermédiaires cachées composent un CNN. Ces couches effectuent des opérations qui modifient les données afin d’apprendre les caractéristiques spécifiques de ces données. Ces opérations se répètent en dizaines ou centaines de couches. Ainsi, chaque couche apprenne à identifier des caractéristiques différentes.
Poids partagé et valeurs de biais
Comme un réseau de neurones traditionnel, un CNN se compose de neurones avec des poids et des biais. Le modèle apprend ces valeurs au cours du processus de formation et les met continuellement à jour à chaque nouvel exemple de formation. Cependant, dans le cas des CNN, les valeurs des poids et des biais sont les mêmes pour tous les neurones cachés dans une couche spécifique.
Cela signifie que tous les neurones cachés détectent la même caractéristique telle qu’une bordure ou un point dans différentes régions de l’image. Cela permet au réseau de tolérer la traduction d’objets dans une image. Par exemple, un réseau formé à la reconnaissance des voitures pourra le faire partout où la voiture se trouve sur l’image.
Couches de classification
Après avoir appris les fonctionnalités multicouches, l’architecture d’un CNN passe à la classification. L’avant-dernière couche est entièrement connectée et produit un vecteur K-dimensionnel. Ici, K est le nombre de classes que le réseau pourra prédire. Ce vecteur contient les probabilités pour chaque classe de toute image classée. La couche finale de l’architecture CNN utilise une couche de classification pour fournir la sortie de classification.
Avantages d’un CNN dans le domaine de la reconnaissance d’images
Comparé aux réseaux neuronaux conventionnels, le CNN offre de nombreux avantages :
Il convient aux applications d’apprentissage automatique et d’Intelligence artificielle avec de grandes quantités de données d’entrée telles que la reconnaissance d’images.
Le réseau fonctionne de manière robuste et est insensible à la distorsion ou à d’autres changements optiques.
Il peut traiter des images enregistrées dans différentes conditions d’éclairage et dans différentes perspectives. Les caractéristiques typiques d’une image sont ainsi facilement identifiées.
Il nécessite beaucoup moins d’espace de stockage que les réseaux de neurones entièrement maillés. Le CNN est divisé en plusieurs couches locales partiellement maillées. Les couches de convolution réduisent considérablement les besoins de stockage.
Le temps de formation d’un CNN est également considérablement réduit. Grâce à l’utilisation de processeurs graphiques modernes, les CNN peuvent être formés de manière très efficace.
Il est la technologie de pointe pour le Deep Learning et la classification dans la reconnaissance d’images (image recognition).
Application d’un CNN dans le domaine du marketing
Le CNN est présent dans divers domaines depuis ces dernières années. La biologie l’utilise principalement pour en savoir plus sur le cerveau. En médecine, il fonctionne parfaitement pour la prédiction de tumeurs ou d’anomalies ainsi que pour l’élaboration de diagnostics complexes et de traitements à suivre en fonction des symptômes. Un autre domaine dans lequel il est couramment utilisé est celui de l’environnement. Il permet d’analyser les tendances et les modèles ou les prévisions météorologiques. Dans le domaine de la finance, il est couramment utilisé dans tout ce qui concerne la prévision de l’évolution des prix, l’évaluation ou l’identification du risque de contrefaçon.
Un CNN a de ce fait une application directe dans de nombreux domaines. Et pour faire face à l’accroissement de la quantité de données disponibles, il est également utilisé dans le marketing. En effet, dans le domaine des affaires et plus particulièrement en marketing, il a plusieurs usages :
Prédiction des ventes
Identification des modèles de comportement
Reconnaissance des caractères écrits
Prédiction du comportement des consommateurs
Personnalisation des stratégies marketing
Création et compréhension des segments d’acheteurs plus sophistiqués
Automatisation des activités marketing
Création de contenu
De toutes ses utilisations, la plus grande se trouve dans l’analyse prédictive. Le CNN aide les spécialistes du marketing à faire des prédictions sur le résultat d’une campagne, en reconnaissant les tendances des campagnes précédentes.
Actuellement, avec l’apparition du Big Data, cette technologie est vraiment utile pour le marketing. Les entreprises ont accès à beaucoup données. Grâce au travail de leur équipe experte dans la data science (data scientist, data analyst, data engineer), le développement de modèles prédictifs est beaucoup plus simple et précis. Les spécialistes du marketing pourront ainsi mieux ciblés les prospects alignés sur leurs objectifs.
Le métier de data engineer est l’une des spécialisations qui se généralise dans l’écosystème Big Data. Selon un rapport de LinkedIn sur les offres d’emploi émergentes de 2020, le poste de data engineer fait partie des 15 professions les plus importantes des cinq dernières années. Il se place aux côtés des autres nouveaux métiers tels que les experts de la data science et de l’Intelligence Artificielle (IA) ainsi que des ingénieurs en fiabilité de site.
Cependant, beaucoup de gens se demandent encore s’ils seraient à l’aise de travailler en tant que data engineer. Est-ce un cheminement de carrière intéressant ? Nous apportons des éléments de réponse dans cet article en définissant succinctement ce qu’il est, ce qu’il fait ainsi que les connaissances et compétences qu’il doit avoir.
Qu’est-ce qu’un data engineer ?
L’ingénieur de données est le professionnel chargé de l’acquisition, du stockage, de la transformation et de la gestion de données dans une organisation. Ce professionnel assume la configuration de l’infrastructure technologique nécessaire pour que les volumes de données de l’entreprise deviennent une matière première accessible pour d’autres spécialistes du Big Data tels que les data analysts et les data scientists.
Les data engineers travaillent sur la conception de pipelines de données, sur la création et la maintenance de l’architecture de ces données. Pour faire simple, le data engineering consiste à veiller à ce que les travaux ultérieurs d’exploitation, d’analyse et d’interprétation des informations puissent être effectués sans incident.
Que fait un data engineer au quotidien ?
Le quotidien d’un data engineer consiste à travailler avec des outils ETL (Extract – Transform – Load). Grâce à une technologie d’intelligence artificielle basée sur des algorithmes de Machine learning, il développe des tâches d’extraction, de transformation et de chargement de données. Ensuite, il les déplace entre différents environnements et les nettoie de toute erreur pour qu’elles arrivent normalisées et structurées aux mains du data scientist et data analyst.
En ce sens, le rôle du data engineer est comparable à celui d’un plombier. Il consiste à mettre en place et à entretenir le réseau de canalisations à travers lequel les données vont passer. Ainsi, il garantit le bon fonctionnement de l’ensemble de l’organisation.
1.Extraction
Dans la première étape du processus ETL, le data engineer prend les données de différents endroits et étudie l’incorporation de nouvelles sources dans le flux de données de l’entreprise. Ces données sont présentées dans différents formats et intègrent des variables très diverses. Ensuite, elles vont vers des data lakes ou un autre type de référentiel où le stockage de données est fait de manière brute et facilement accessible pour toute utilisation future.
2.Transformation
Dans la deuxième étape, le data engineer procède au nettoyage des données. Il élimine les doublons et corrige les erreurs. Puis, il les classe pour les transformer en un ensemble homogène.
3.Chargement
Dans la dernière étape, le data engineer charge les données vers leur destination. Il peut s’agir des propres serveurs de l’entreprise ou du Cloud. À part cela, il doit également veiller sur un point important de cette étape finale : la sécurité des données. En effet, il doit garantir que les informations soient correctement protégées des cyberattaques et des accès non autorisés.
Quelles connaissances doit avoir un data engineer ?
Tout d’abord, il doit avoir une connaissance courante des bases de données relationnelles et du langage de requête SQL. Cela lui permet de connaître les techniques de modélisation de données les plus utilisées et de savoir comment accéder aux données sources lorsqu’elles sont disponibles.
Il doit aussi connaître les techniques de nettoyage, de synthèse et de validation des données. Ainsi, les informations parviennent à leurs utilisateurs de manière adaptée pour leur exploitation correcte.
Il doit également savoir utiliser de manière optimale les moteurs de traitement de Big Data tels que Spark ou Flink.
Quelles technologies sont essentielles pour un data engineer ?
Les technologies utilisées par le data engineer comprennent les bases de données non relationnelles et les méthodes de modélisation des données. Parmi ces technologies, on peut citer comme exemple HBASE, Cassandra ou MongoDb. Il est aussi intéressant qu’il sache utiliser les moteurs d’indexation tels que SolR et ElasticSearch.
Dans les systèmes de collecte de données d’aujourd’hui, il est très important pour ce professionnel de maîtriser les technologies qui lui permettent d’y accéder en temps réel. On parle généralement de technologies de streaming comme Flume, Kafka ou Spark Structured Streaming.
Son système d’exploitation habituel est Linux où il doit maîtriser parfaitement l’environnement. Côté langages de programmation, les plus communs sont Java, Scala ou Kotlin pour le développement de processus de traitement de données. Concernant Python, il sert pour l’analyse et la préparation préalable des données.
Par ailleurs, il est de plus en plus important qu’il ait une connaissance du développement d’applications natives pour le Cloud. Aujourd’hui, c’est un mouvement que de nombreuses entreprises suivent. Connaître les différences entre le développement d’applications locales et basées sur le Cloud est nécessaire. La principale raison est la transition en toute sécurité.
Enfin, l’ingénieur de données doit pouvoir évoluer en toute confiance dans un grand nombre de domaines différents de l’informatique. Il ne doit jamais cesser d’apprendre et d’ajouter de nouveaux outils à ses bagages professionnels.
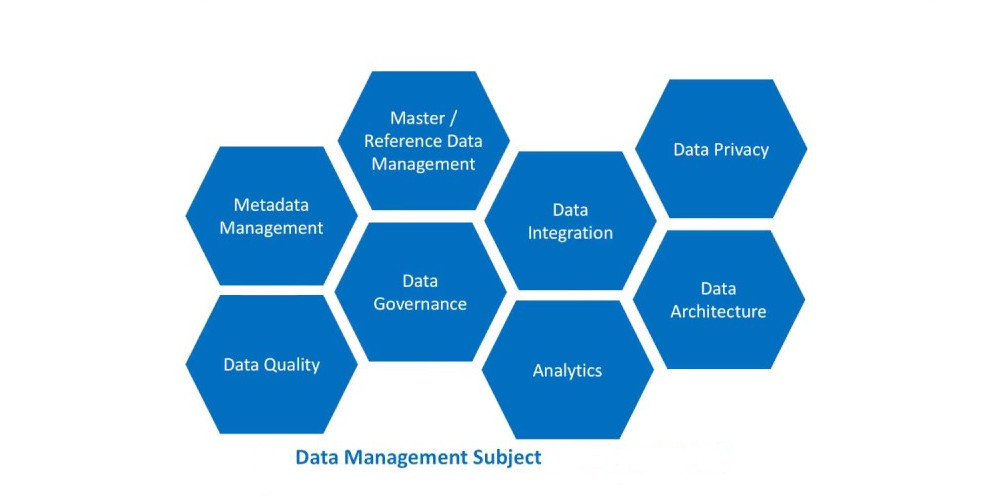
Le concept de data management ou gestion des données comprend une liste complète de sujets associés et connexes qui couvrent l’ensemble du processus de gestion et d’exploitation des données. Dans cette liste, nous pouvons trouver des termes tels que l’architecture de données, la modélisation de données, l’intégration de données, la qualité des données, le Big Data la confidentialité et la sécurité des données. Il s’agit d’une partie du Business intelligence permettant, au même titre que les autres éléments clé de la data science, de mettre en place des outils optimisant la prise de décisions.
Qu’est-ce que le data management ?
On entend souvent parler de la gouvernance des données ou data governance. Mais, il ne s’agit que d’un élément clé du data management. Et la gestion des données est un ensemble complet de pratiques, de concepts, de procédures et de processus. C’est également un large éventail de systèmes complémentaires qui permettent à une organisation de prendre le contrôle de ses ressources d’informations, de la collecte à la sécurisation des données.
Le data management en tant que pratique générale concerne le cycle de vie complet de données de référence depuis leur point de création d’origine jusqu’à leur mise hors service finale.
Concepts autour du data management
Beaucoup de questions sont posées autour du sujet « data management » :
Est-il facile d’accéder, de nettoyer, d’intégrer et de stocker les données personnelles des gens ?
Quel type de données les acteurs au sein de l’entreprise utilisent-ils ?
L’entreprise dispose-t-elle d’un système efficace pour une analyse de données au fur et à mesure qu’elles circulent en interne ?
Ces questions invitent à comprendre certains concepts permettant de connaître en profondeur ce qu’est réellement la gestion des données :
1.Accès aux données
Ce terme fait référence à la capacité d’accéder et de récupérer des informations où qu’elles soient. Certaines technologies peuvent rendre cette étape aussi simple et efficace que possible afin que les entreprises puissent utiliser les données et ne pas seulement les trouver.
2.Qualité des données
Il faut s’assurer que les données soient exactes et utilisables aux fins prévues. Cela commence à partir du moment où elles sont trouvées et se poursuit via divers points d’intégration avec d’autres données.
3.Intégration de données
Ce terme définit les étapes pour combiner différents types de données. Les outils d’intégration de données permettent de concevoir et d’automatiser les étapes.
4.Contrôle des données
Il s’agit d’un ensemble continu de règles et de décisions permettant de gérer les données d’une entreprise afin de garantir que la stratégie sur ces données est alignée celle de l’entreprise.
5.Master data management (MDM)
Unification et gestion de toutes les données communes et essentielles à tous les domaines d’une organisation. Ces données de base sont généralement gérées à partir d’un seul emplacement ou concentrateur.
6.Transmission de données
Implique l’analyse des données au fur et à mesure qu’elles se déplacent en appliquant une logique aux données : identification des modèles dans les données et filtration pour des utilisations multiples à mesure qu’elles circulent dans l’organisation.
Avantages apportés par le data management
Pour une entreprise, le data management est la première étape dans la gestion d’un volume de données à la fois structurées et non structurées. Mais, ce n’est que grâce aux meilleures pratiques qu’elle peut exploiter la puissance de ces données. C’est également l’unique solution pour obtenir les informations dont elle a besoin pour rendre les données utiles.
En fait, le data management permet aux organisations d’utiliser l’analyse des données à des fins de marketing et de relation client :
Personnaliser l’expérience client
Ajouter de la valeur aux interactions avec les clients
Identifier en temps réel les causes des échecs marketing
Récolter les revenus associés au marketing axé sur les données
Améliorer l’engagement client
Augmenter la fidélité des clients
Bonnes pratiques dans le data management
Dans toute opération de data management, il faut savoir gérer les données et acquérir les connaissances nécessaires pour prendre de bonnes décisions. Pour ce faire, il faut commencer par se poser une question d’ordre commerciale et acquérir les données nécessaires pour y répondre.
Les entreprises collectent de grandes quantités d’informations à partir de diverses sources. Elles utilisent ensuite les meilleures pratiques tout au long du processus de stockage et de gestion, de nettoyage et d’extraction des données. Enfin, elles procèdent à l’analyse et la visualisation des données pour éclairer leurs décisions commerciales.
Il est important de noter que les meilleures pratiques de gestion des données se traduisent par des améliorations analytiques en même temps. En gérant et en préparant correctement les données pour l’analyse, les entreprises optimisent leur Big Data.
Certaines des meilleures pratiques de data management que les entreprises cherchent désespérément à mettre en œuvre sont :
La simplification de l’accès aux données traditionnelles et émergentes.
Le nettoyage des données pour insuffler de la qualité dans les processus métier existants
Le façonnage des données à l’aide de techniques de manipulation flexibles
Le métier de data analyst est de plus en plus prisé sur le marché du travail. Toutes sortes d’entreprises recherchent ses compétences. Tout le monde parle du Big Data, de l’apprentissage automatique ou Machine Learning, du traitement de données, de la gestion de l’analyse de données et de l’exploration de données.
Dans cet article, nous allons apporter des explications sur le cœur de métier d’un analyste de données et tout ce qu’il apprend tout le long de la formation data analyst.
Le Big Data : centre de gravité de la formation data analyst
Bon nombre de jeunes diplômés se demandent encore pourquoi suivre une formation en Big Data. La réponse peut se résumer comme suit : parce que c’est ainsi qu’ils peuvent s’assurer d’avoir un emploi à l’avenir.
Beaucoup ne savent pas encore ce qu’est l’analyse de données. Pour résumer, il s’agit du moyen de rendre toutes les données acquises dans l’environnement numérique compréhensibles et utiles pour les entreprises à travers son analyse et sa gestion. Différents domaines de l’entreprise en bénéficie : marketing, commerce, relation client ou CRM, etc. Pour ce faire, le data analyst travaille avec des méthodologies de business intelligence et des outils logiciels spécifiques.
Que fait un data analyst ?
Il est important de connaître les principales fonctions d’un data analyst avant d’avoir un projet professionnel d’en devenir un.
1. Identification des données
La première chose qu’un data analyst fait avant d’analyser et de traiter les données est d’identifier les informations. Il s’agit uniquement des données qui intéressent l’entreprise depuis différentes sources. Pour ce faire, il doit structurer ou ordonner toutes ces données dans des graphiques et des tableaux pour en faire une présentation adéquate.
2. Établir des directives sur le comportement des clients
Une des principales fonctions du data analyst est de mettre en œuvre les stratégies nécessaires pour guider l’entreprise en fonction du comportement des clients. Les canaux numériques sont généralement les principaux domaines concernés. En effet, des actions plus personnalisées doivent être menées pour déterminer exactement ce que le public souhaite.
3. Traitement et regroupement des informations
L’analyste de données doit développer un traitement de données ardu à travers des opérations mathématiques et l’utilisation de langages de programmation. Il faut ensuite les regrouper par catégories d’informations pour les ordonner et en tirer des conclusions à forte valeur ajoutée pour l’entreprise.
4. Effectuer une communication transparente avec l’organisation
Travailler en tant que data analyst est en réalité devenir le gardien de toutes les informations traitées par l’entreprise. Son rôle est de générer des rapports. Ces derniers sont destinés aux services qui bénéficient des données analysées. Par conséquent, ils doivent être conforme au domaine d’activité de l’entreprise. D’une certaine manière, il interprète les données pour en tirer des informations utiles pour la prise de décision.
Pré requis pour suivre une formation data analyst
Pour devenir data analyst, il est nécessaire de répondre aux exigences essentielles répondant aux rigueurs du poste.
Niveau d’étude minimum
Devenir un data analyst n’est pas à la portée de quelqu’un ayant un niveau bac. Il faut au minimum avoir suivi une formation dans une école de marketing ou une école spécialisée dans le digital. Il existe toutefois plusieurs formations dispensées par des écoles d’informatique, des centres de formation et même par Pôle Emploi.
Par ailleurs, il n’est pas rare de voir l’analyse de données comme une spécialisation. C’est le cas notamment dans certains cursus pour l’obtention d’une Licence professionnelle, d’un Master ou d’un Master spécialisée.
Capacité de synthèse de données
Il est nécessaire d’avoir la capacité de synthétiser des données pour savoir comment choisir et extraire les informations les plus pertinentes et utiles pour l’entreprise. Il est très important de connaître ses objectifs au même titre que le secteur dans lequel elle opère. La détection des problèmes et leur résolution grâce à une analyse exhaustive de leurs caractéristiques fait ensuite appel à cette extraction de données.
Communication fluide avec les parties prenantes
Il est nécessaire pour le data analyst d’avoir une communication fluide avec les dirigeants et les managers. Ce sont des pré-requis pour pouvoir expliquer les résultats de manière précise sans entrer dans les détails techniques. Un langage simple permettra à la direction de mieux comprendre la portée des conclusions de l’analyse.
Langage de programmation
Un data analyst doit avoir de bonnes compétences informatiques et savoir gérer les langages de programmation. En même temps, il doit maîtriser les mathématiques statistiques pour développer une analyse adéquate et tirer des conclusions d’un point de vue critique et objectif.
Transformer les données en recommandations est l’une des qualités les plus appréciées par les employeurs. C’est pour cela qu’ils décident d’inclure un data scientist et un data analyst parmi leur personnel.
Qu’apprend-on d’une formation data analyst ?
On peut trouver facilement en ligne une formation data analyst . Que ce soit chez Pôle Emploi ou via une formation mise en place à distance, il existe de multiples sujets traités. Certains sont souvent abordés jusqu’à la fin de la formation :
Fondamentaux du Big Data (techniques et concepts)
Data science (comprendre la science des données)
Comprendre le Big Data (analyse et visualisation des données)
Comprendre l’analyse des données (Power BI)
Business Intelligence (différence avec l’analyse de données)
L’utilisation quotidienne de services tels que les médias sociaux, la navigation mobile et la numérisation de toutes les transactions font depuis longtemps partie de la vie quotidienne. D’énormes quantités de données en découlent. Non seulement de nouvelles apparaissent chaque jour, mais elles augmentent de façon exponentielle d’année en année.
Les entreprises utilisent ces données au quotidien pour prendre des décisions stratégiques. Le rôle du data scientist est de créer une base de données structurée à partir de ces données brutes. Il y apporte ensuite son analyse et les traite afin qu’elles aient de la valeur et soient utiles (à des fins marketings par exemple).
À première vue, le rôle d’un data scientist semble se résumer à valoriser le Big Data. Cependant, la taille des données et leur caractère hétérogène sont des facteurs qui complexifient ses tâches.
Quelles sont les missions d’un data scientist ?
Le data scientist est un expert du Big Data. Il ne fait pas que collecter des données, mais les traite et les valorise en ce qu’on appelle communément le Smart Data. Pour ce faire, il effectue des analyses avancées via des outils de Business Intelligence (BI) qui s’occupent des processus et des procédures d’analyse commerciale.
Les outils d’analyse de Business Intelligence examinent principalement les données historiques. Les analyses qui sont ainsi réalisées par le data scientist sont non seulement plus avancées sur le plan technologique, mais se concentrent souvent sur la prédiction des tendances. L’analyse prédictive fait partie des analyses avancées faites par cet expert du Big Data. Cela lui permet d’évaluer les effets de certains changements futurs.
Mais avant d’en venir à l’analyse, le data scientist s’assure d’abord qu’il dispose d’une base de données solide. Sans cela, il ne peut apporter des prédictions fiables.
Toutefois, même s’il travaille sur des données brutes, le data scientist n’a pas de difficulté à analyser des données non structurées. En effet, elles le sont généralement au début de leur cycle de vie. Dans ce bric-à-brac d’informations, son travail consiste à extraire uniquement les données pertinentes. Ensuite, il les filtre par ordre d’importance et à les cartographie grâce à des outils de cartographie. Il convertit également l’ensemble de données triées dans le format approprié.
Quelles sont les compétences requises pour devenir data scientist ?
Des connaissances dans des domaines techniques tels que les bases de données ou le génie logiciel sont aussi importants. En effet, le data scientist doit maîtriser des langages de programmation tels que Python ou Java pour développer des algorithmes lui permettant d’utiliser à bon escient les données qui lui sont confiées.
Il doit aussi avoir de solides connaissances dans diverses disciplines. On peut citer les mathématiques et les statistiques. Elles lui permettent de développer des modèles prédictifs qui seront des outils d’aide à la décision. Bien entendu, ses connaissances en mathématiques lui sont utiles pour pouvoir travailler sur des bases de données SQL et NoSQL.
Outre l’aspect académique de ses compétences, le data scientist doit également avoir un esprit analytique. En ce sens, il doit avoir la capacité de réagir de manière rationnelle face à un problème, de faire preuve de logique par rapport à ses décisions.
Quelles formations suivre pour être data scientist expert ?
En France, les cours et formations sur le métier de data scientist se multiplient. Quiconque étudie la science des données acquiert les compétences de base avec lesquelles les données peuvent être scientifiquement traitées et évaluées à des fins commerciales. Il existe également des cours de perfectionnement. Ils s’adressent aux personnes ayant déjà étudié les mathématiques, l’informatique ou les statistiques et qui souhaitent poursuivre leur développement professionnel.
Les grandes écoles françaises comme HEC, INP, IAMD (Telecom Nancy), ENSAE ParisTech et Télécom Paris Tech ont récemment ajouté à leurs formations en ingénierie informatique ou en mathématique des cours à destination des candidats au métier de data scientist. Parallèlement, des centres de formation se développent. Ils apportent des solutions répondant aux attentes des entreprises et des particuliers cherchant à devenir un expert de la data science.
Quels sont les salaires proposés aux data scientists ?
La science des données est un secteur qui est encore en plein développement. Mais, les métiers qui y sont liés comme celui du data scientist bénéficient d’une excellente notoriété que les salaires attirent de plus en plus de jeunes diplômés et personnes en réorientation professionnelle.
Pour un débutant, il peut espérer un salaire net de 35 000 et 38 000 euros par an. Dès lors qu’il a acquis de l’expérience (4 ans minimum), il peut gagner 10 000 à 15 000 euros de plus. Pour le cas d’un data scientist confirmé et expert, le salaire peut aller jusqu’à 60 000 euros par an.
La Computer Vision ou vision par ordinateur est une technologie d’intelligence artificielle permettant aux machines d’imiter la vision humaine. Découvrez tout ce que vous devez savoir : définition, fonctionnement, histoire, applications, formations…
Depuis maintenant plusieurs années, nous sommes entrés dans l’ère de l’image. Nos smartphones sont équipés de caméras haute définition, et nous capturons sans cesse des photos et des vidéos que nous partageons au monde entier sur les réseaux sociaux.
Les services d’hébergement vidéo comme YouTube connaissent une popularité explosive, et des centaines d’heures de vidéo sont mises en ligne et visionnées chaque minute. Ainsi, l’internet est désormais composé aussi bien de texte que d’images.
Toutefois, s’il est relativement simple d’indexer les textes et de les explorer avec des moteurs de recherche tels que Google, la tâche est bien plus difficile en ce qui concerne les images. Pour les indexer et permettre de les parcourir, les algorithmes ont besoin de connaître leur contenu.
Pendant très longtemps, la seule façon de présenter le contenu d’une image aux ordinateurs était de renseigner sa méta-description lors de la mise en ligne. Désormais, grâce à la technologie de ” vision par ordinateur ” (Computer Vision), les machines sont en mesure de ” voir “ les images et de comprendre leur contenu.
Qu’est ce que la vision par ordinateur ?
La Computer Vision peut être décrite comme un domaine de recherche ayant pour but de permettre aux ordinateurs de voir. De façon concrète, l’idée est de transmettre à une machine des informations sur le monde réel à partir des données d’une image observée.
Pour le cerveau humain, la vision est naturelle. Même un enfant est capable de décrire le contenu d’une photo, de résumer une vidéo ou de reconnaître un visage après les avoir vus une seule fois. Le but de la vision par ordinateur est de transmettre cette capacité humaine aux ordinateurs.
Il s’agit d’un vaste champ pluridisciplinaire, pouvant être considéré comme une branche de l’intelligence artificielle et du Machine Learning. Toutefois, il est aussi possible d’utiliser des méthodes spécialisées et des algorithmes d’apprentissage général n’étant pas nécessairement liés à l’intelligence artificielle.
De nombreuses techniques en provenance de différents domaines de science et d’ingénierie peuvent être exploitées. Certaines tâches de vision peuvent être accomplies à l’aide d’une méthode statistique relativement simple, d’autres nécessiteront de vastes ensembles d’algorithmes de Machine Learning complexes.
En 1966, les pionniers de l’intelligence artificielleSeymour Papert et Marvin Minsky lance le Summer Vision Project : une initiative de deux mois, rassemblant 10 hommes dans le but de créer un ordinateur capable d’identifier les objets dans des images.
Pour atteindre cet objectif, il était nécessaire de créer un logiciel capable de reconnaître un objet à partir des pixels qui le composent. À l’époque, l’IA symbolique – ou IA basée sur les règles – était la branche prédominante de l’intelligence artificielle.
Les programmeurs informatiques devaient spécifiermanuellement les règles de détection d’objets dans les images. Or, cette approche pose problème puisque les objets dans les images peuvent apparaître sous différents angles et différents éclairages. Ils peuvent aussi être altérés par l’arrière-plan, ou obstrués par d’autres objets.
Les valeurs de pixels variaient donc fortement en fonction de nombreux facteurs, et il était tout simplement impossible de créer des règlesmanuellement pour chaque situation possible. Ce projet se heurta donc aux limites techniques de l’époque.
Quelques années plus tard, en 1979, le scientifique japonais Kunihiko Fukushima créa un système de vision par ordinateur appelé ” neocognitron “ en se basant sur les études neuroscientifiques menées sur le cortex visuel humain. Même si ce système échoua à effectuer des tâches visuelles complexes, il posa les bases de l’avancée la plus importante dans le domaine de la Computer Vision…
La révolution du Deep Learning
La Computer Vision n’est pas une nouveauté, mais ce domaine scientifique a récemment pris son envol grâce aux progrès effectués dans les technologies d’intelligence artificielle, de Deep Learninget de réseaux de neurones.
Dans les années 1980, le Français Yan LeCun crée le premier réseau de neurones convolutif : une IA inspirée par le neocognitron de Kunihiko Fukushima. Ce réseau est composé de multiples couches de neurones artificiels, des composants mathématiques imitant le fonctionnement de neurones biologiques.
Lorsqu’un réseau de neurones traite une image, chacune de ses couches extrait des caractéristiques spécifiques à partir des pixels. La première couche détectera les éléments les plus basiques, comme les bordures verticales et horizontales.
À mesure que l’on s’enfonce en profondeur dans ce réseau, les couches détectent des caractéristiques plus complexes comme les angles et les formes. Les couches finales détectent les éléments spécifiques comme les visages, les portes, les voitures. Le réseau produit enfin un résultat sous forme de tableau de valeurs numériques, représentant les probabilités qu’un objet spécifique soit découvert dans l’image.
L’invention de Yann LeCun est brillante, et a ouvert de nouvelles possibilités. Toutefois, son réseau de neurones était restreintpar d’importantes contraintes techniques. Il était nécessaire d’utiliser d’immenses volumes de données et des ressources de calcul titanesques pour le configurer et l’utiliser. Or, ces ressources n’étaient tout simplement pas disponibles à cette époque.
Dans un premier temps, les réseaux de neurones convolutifs furent donc limités à une utilisation dans les domaines tels que les banques et les services postaux pour traiter des chiffres et des lettres manuscrites sur les enveloppes et les chèques.
Il a fallu attendre 2012 pour que des chercheurs en IA de Toronto développentle réseau de neurones convolutif AlexNet et triomphent de la compétition ImageNet dédiée à la reconnaissance d’image. Ce réseau a démontré que l’explosion du volume de données et l’augmentation de puissance de calcul des ordinateurs permettaient enfin d’appliquer les ” neural networks ” à la vision par ordinateur.
Ce réseau de neurones amorça la révolution du Deep Learning : une branche du Machine Learning impliquant l’utilisation de réseaux de neurones à multiples couches. Ces avancées ont permis de réaliser des bonds de géants dans le domaine de la Computer Vision. Désormais, les machines sont même en mesure de surpasser les humains pour certaines tâches de détection et d’étiquetage d’images.
Comment fonctionne la vision par ordinateur
Les algorithmes de vision par ordinateur sont basés sur la ” reconnaissance de motifs “. Les ordinateurs sont entraînés sur de vastes quantités de données visuelles. Ils traitent les images, étiquettent les objets, et trouvent des motifs (patterns) dans ces objets.
Par exemple, si l’on nourrit une machine avec un million de photos de fleurs, elle les analysera et détectera des motifs communs à toutes les fleurs. Elle créera ensuite un modèle, et sera capable par la suite de reconnaître une fleurchaque fois qu’elle verra une image en comportant une.
Les algorithmes de vision par ordinateur reposent sur les réseaux de neurones, censés imiter le fonctionnement du cerveau humain. Or, nous ne savons pas encore exactement comment le cerveau et les yeux traitent les images. Il est donc difficile de savoir à quel point les algorithmes de Computer Vision miment ce processus biologique.
Les machines interprètent les images de façon très simple. Elles les perçoivent comme des séries de pixels, avec chacun son propre ensemble de valeurs numériques correspondant aux couleurs. Une image est donc perçue comme une grille constituée de pixels, chacun pouvant être représenté par un nombre généralement compris entre 0 et 255.
Bien évidemment, les chosesse compliquent pour les images en couleur. Les ordinateurs lisent les couleurs comme des séries de trois valeurs : rouge, vert et bleu. Là encore, l’échelle s’étend de 0 à 255. Ainsi, chaque pixel d’une image en couleur à trois valeurs que l’ordinateur doit enregistrer en plus de sa position.
Chaque valeur de couleur est stockée en 8 bits. Ce chiffre est multiplié par trois pour une image en couleurs, ce qui équivaut à 24 bits par pixel. Pour une image de 1024×768 pixels, il faut donc compter 24 bits par pixels soit presque 19 millions de bits ou 2,36 mégabytes.
Vous l’aurez compris : il faut beaucoup de mémoire pour stocker une image. L’algorithme de Computer Vision quant à lui doit parcourir un grand nombre de pixels pour chaque image. Or, il faut généralement plusieurs dizaines de milliers d’images pour entraîner un modèle de Deep Learning.
C’est la raison pour laquelle la vision par ordinateur est une discipline complexe, nécessitant une puissance de calcul et une capacité de stockage colossales pour l’entraînement des modèles. Voilà pourquoi il a fallu attendre de nombreuses années pour que l’informatique se développe et permette à la Computer Vision de prendre son envol.
Les différentes applications de Computer Vision
La vision par ordinateur englobe toutes les tâches de calcul impliquant le contenu visuel telles que les images, les vidéos ou même les icônes. Cependant, il existe de nombreuses branchesdans cette vaste discipline.
La classification d’objet consiste à entraîner un modèle sur un ensemble de données d’objets spécifiques, afin de lui apprendre à classer de nouveaux objets dans différentes catégories. L’identification d’objet quant à elle vise à entraîner un modèle à reconnaître un objet.
Parmi les applications les plus courantes de vision par ordinateur, on peut citer la reconnaissance d’écriture manuscrite. Un autre exemple est l’analyse de mouvement vidéo, permettant d’estimer la vélocité des objets dans une vidéo ou directement sur la caméra.
Dans la segmentation d’image, les algorithmes répartissent les images dans plusieurs ensembles de vues. La reconstruction de scène permet de créer un modèle 3D d’une scène à partir d’images et de vidéos.
Enfin, la restauration d’imageexploite le Machine Learning pour supprimer le ” bruit ” (grain, flou…) sur des photos. De manière générale, toute application impliquant la compréhension des pixels par un logiciel peut être associée à la Computer Vision.
Quels sont les cas d’usages de la Computer Vision ?
La Computer Vision fait partie des applications du Machine Learning que nous utilisons déjà au quotidien, parfois sans même le savoir. Par exemple, les algorithmes de Googleparcourent des cartes pour en extraire de précieuses données et identifier les noms de rues, les commerces ou les bureaux d’entreprises.
De son côté, Facebook exploite la vision par ordinateurafin d’identifier les personnes sur les photos. Sur les réseaux sociaux, elle permet aussi de détecter automatiquement le contenu problématique pour le censurer immédiatement.
Les entreprises de la technologie sont loin d’être les seules à se tourner vers cette technologie. Ainsi, le constructeur automobile Ford utilise la Computer Vision pour développer ses futurs véhicules autonomes. Ces derniers reposent sur l’analyse en temps réel de nombreux flux vidéo capturés par la voiture et ses caméras.
Il en va de même pour tous les systèmes de voitures sans pilote comme ceux de Tesla ou Nvidia. Les caméras de ces véhicules capturent des vidéos sous différents angles et s’en servent pour nourrir le logiciel de vision par ordinateur.
Ce dernier traite les images en temps réel pour identifier les bordures des routes, lire les panneaux de signalisation, détecter les autres voitures, les objets et les piétons. Ainsi, le véhicule est en mesure de conduire sur autoroute et même en agglomération, d’éviter les obstacles et de conduire les passagers jusqu’à leur destination.
La santé
Dans le domaine de la santé, la Computer Vision connaît aussi un véritable essor. La plupart des diagnostics sont basés sur le traitement d’image : lecture de radiographies, scans IRM…
Google s’est associé avec des équipes de recherche médicalepour automatiser l’analyse de ces imageries grâce au Deep Learning. D’importants progrès ont été réalisés dans ce domaine. Désormais, les IA de Computer Vision se révèlent plus performantes que les humains pour détecter certaines maladies comme la rétinopathie diabétique ou divers cancers.
Le sport
Dans le domaine du sport, la vision par ordinateur apporte une précieuse assistance. Par exemple, la Major League Baseballutilise une IA pour suivre la balle avec précision. De même, la startup londonienne Hawk-Eye déploie son système de suivi de balle dans plus de 20 sports comme le basketball, le tennis ou le football.
La reconnaissance faciale
Une autre technologie reposant sur la Computer Vision est la reconnaissance faciale. Grâce à l’IA, les caméras sont en mesure de distinguer et de reconnaître les visages. Les algorithmes détectent les caractéristiques faciales dans les images, et les comparent avec des bases de données regroupant de nombreux visages.
Cette technologie est utilisée sur des appareils grand public comme les smartphones pour authentifier l’utilisateur. Elle est aussi exploitée par les réseaux sociaux pour détecter et identifier les personnes sur les photos. De leur côté, les autorités s’en servent pour identifier les criminels dans les flux vidéo.
La réalité virtuelle et augmentée
Les nouvelles technologies de réalité virtuelle et augmentée reposent également sur la Computer Vision. C’est elle qui permet aux lunettes de réalité augmentée de détecter les objets dans le monde réelet de scanner l’environnement afin de pouvoir y disposer des objets virtuels.
Par exemple, les algorithmes peuvent permettre aux applications AR de détecter des surfaces planes comme des tables, des murs ou des sols. C’est ce qui permet de mesurer la profondeur et les dimensionsde l’environnement réel pour pouvoir y intégrer des éléments virtuels.
Les limites et problèmes de la Computer Vision
La vision par ordinateur présente encore des limites. En réalité, les algorithmes se contentent d’associer des pixels. Ils ne ” comprennent ” pas véritablement le contenu des images à la manière du cerveau humain.
Pour cause, comprendre les relations entre les personnes et les objets sur des images nécessite un sens commun et une connaissance du contexte. C’est précisément pourquoi les algorithmes chargés de modérer le contenu sur les réseaux sociaux ne peuvent faire la différence entre la pornographie et une nudité plus candide comme les photos d’allaitement ou les peintures de la Renaissance.
Alors que les humains exploitent leur connaissance du monde réel pour déchiffrer des situations inconnues, les ordinateurs en sont incapables. Ils ont encore besoin de recevoir des instructions précises, et si des éléments inconnusse présentent à eux, les algorithmes dérapent. Un véhicule autonome sera par exemple pris de cours face à un véhicule d’urgence garé de façon incongrue.
Même en entraînant une IA avec toutes les données disponibles, il est en réalité impossible de la préparer à toutes les situations possibles. La seule façon de surmonter cette limite serait de parvenir à créer une intelligence artificielle générale, à savoir une IA véritablement similaire au cerveau humain.
Comment se former à la Computer Vision ?
Si vous êtes intéressé par la Computer Vision et ses multiples applications, vous devez vous former à l’intelligence artificielle, au Machine Learning et au Deep Learning. Vous pouvez opter pour les formations DataScientest.
Le Machine Learning et le Deep Learning sont au coeur de nos formations Data Scientist et Data Analyst. Vous apprendrez à connaître et à manier les différents algorithmes et méthodes de Machine Learning, et les outils de Deep Learning comme les réseaux de neurones, les GANs, TensorFlow et Keras.
Ces formations vous permettront aussi d’acquérir toutes les compétences nécessaires pour exercer les métiers de Data Scientist et de Data Analyst. À travers les différents modules, vous pourrez devenir expert en programmation, en Big Data et en visualisation de données.
Nos différentes formations adoptent une approche innovante de Blended Learning, alliant le présentiel au distanciel pour profiter du meilleur des deux mondes. Elles peuvent être effectuées en Formation Continue, ou en BootCamp.
Pour le financement, ces parcours sont éligibles au CPF et peuvent être financés par Pôle Emploi via l’AIF. À l’issue du cursus, les apprenants reçoivent un diplôme certifié par l’Université de la Sorbonne. Parmi nos alumnis, 93% trouvent un emploi immédiatementaprès l’obtention du diplôme. N’attendez plus, et découvrez nos formations.
L’apprentissage supervisé, dans le contexte de l’intelligence artificielle, est la méthode d’apprentissage la plus utilisée en Machine Learning et en Deep Learning. L’apprentissage supervisé consiste à surveiller l’apprentissage de la machine en lui présentant des exemples de ce qu’elle doit effectuer. Ses utilisations sont nombreuses : reconnaissance vocale, intelligence artificiel
le, classifications, etc. Ainsi, la régression linéaire fait partie d’une des techniques d’apprentissage supervisé la plus utilisée dans la prédiction d’une valeur continue. Aussi, la grande majorité des problèmes de Machine Learning et de Deep Learning utilisent l’apprentissage supervisé : il est donc primordial de comprendre correctement le fonctionnement de cette méthode.
Comment fonctionne un apprentissage supervisé ?
Le but de l’apprentissage automatique est de créer des algorithmes aptes à recevoir des ensembles de données et à réaliser une analyse statistique pour prédire un résultat.
Si on appelle ça un apprentissage supervisé, c’est parce que le processus d’un algorithme tiré du Training Set (ensembles de données) peut être considéré comme un enseignant qui surveille le processus d’apprentissage. Nous connaissons les bonnes réponses, l’algorithme effectue des prédictions sur les réponses et est ensuite corrigé par l’enseignant. L’apprentissage cesse quand l’algorithme atteint le niveau attendu pour être efficient.
Il consiste en des variables d’entrée X et une variable de sortie Y. L’algorithme a pour but d’apprendre la fonction de l’entrée jusqu’à la sortie.
Y = f (X)
Les étapes de l’apprentissage automatique sont :
La collecte des données et leur labellisation
Le nettoyage des données pour identifier de potentielles erreurs ou manquement
Le prétraitement des données (identification des variables explicatives notamment)
Instanciation des modèles (modèle de régression ou de classification par exemple).
Entraînement des modèles
Validation du modèle
Ainsi et comme le montre la formule Y = f (X), le modèle d’apprentissage supervisé est très efficace pour étudier des relations linéaires mais il reste incapable de performer quand il y a des relations plus complexes qu’une linéarité entre les variables.
Apprentissage supervisé ou non supervisé ?
L’apprentissage non supervisé correspond au fait de n’utiliser que des données d’entrée (X) et aucune variable de sortie Y correspondante. Le but de l’apprentissage non supervisé est de modéliser la structure des données afin d’en apprendre plus sur les données et à la différence de l’apprentissage supervisé, il n’y a pas de bonne réponse ni d’enseignant. Les algorithmes sont laissés à leurs propres processus pour étudier et choisir la structure des données qui soit intéressante.
L’apprentissage automatique présente des atouts que les apprentissages non supervisés n’ont pas, mais il rencontre aussi des difficultés. En effet, l’apprentissage supervisé est plus apte à prendre des décisions auxquelles les humains peuvent s’identifier car les données sont elles-mêmes fournies par l’humain. Néanmoins, les apprentissages supervisés rencontrent plus de difficultés à traiter les données qui s’ajoutent après l’apprentissage. En effet, si un système connaît les groupes chiens et chats et reçoit une photographie de souris, il devra la placer dans l’un ou l’autre de ces deux groupes alors qu’elle n’y appartient pas. Au contraire, si le système avait suivi un apprentissage non supervisé, il ne serait pas capable d’identifier que c’est une souris mais il serait capable de le définir comme n’appartenant à aucune des 2 catégories chiens et chats.
Considérons le problème classique de la fidélisation des clients, nous constatons que nous pouvons l’aborder de différentes manières. Une entreprise veut segmenter ses clients. Cependant, quelle est la stratégie la plus appropriée ? Est-il préférable de traiter cela comme un problème de classification, de regroupement ou même de régression ? L’indice clé va nous donner la deuxième question.
Si l’entreprise se demande : « Mes clients se regroupent-ils naturellement d’une manière ou d’une autre ? », il n’y a pas à définir de cible pour le regroupement. En revanche, si elle pose la question autrement : « Pouvons-nous identifier des groupes de clients ayant une forte probabilité de se désabonner dès la fin de leur contrat ? », l’objectif sera bien défini. Par conséquent, elle prendra des mesures en fonction de la réponse à la question qui suit : « Le client va-t-il se désabonner ? ».
Dans le premier cas, nous avons affaire à un exemple d’apprentissage non supervisé, tandis que le second est un exemple d’apprentissage supervisé.
L’apprentissage supervisé chez DataScientest
Considérant l’efficacité et l’importance de l’apprentissage supervisé, DataScientestle place parmi les connaissances à valider aux cours de ses formations. Notamment au sein de la formation de data analyst et dans le module de Machine Learning de 75h, il vous sera demandé d’apprendre à identifier les problèmes de Machine Learning non supervisés, et apprendre à utiliser des méthodes d’apprentissage supervisé par des problèmes de régression. De même, dans la formation de data management, dans le module Data Literacy, nous apprendrons à identifier quelle méthode de Machine Learning utiliser selon le type de métier. Enfin, dans la formation de data scientist, le module de Machine Learning de 75h se verra attribuer une partie conséquente sur le sujet des apprentissages supervisés et non supervisés, leurs mises en place et l’identification de leurs problèmes.
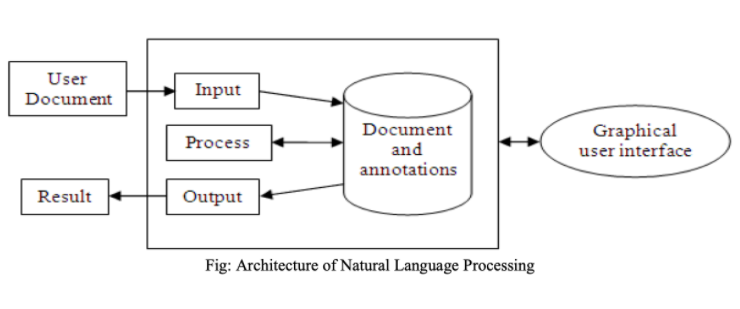
C’est seulement il y a 40 ans que l’objectif de doter les ordinateurs de la capacité de comprendre le langage naturel au sens de courant a commencé. Cet objectif de compréhension du langage naturel par les ordinateurs – plus communément appelé traitement du langage naturel ou “natural language processing” en anglais (NLP)est le sujet de cet article.
La maitrise du NLP permet d’accéder à des opportunités professionnelles dans le secteur de la data science. Seul un data scientist qui maitrise les techniques de machine learning et deep learning sera capable d’utiliser ces modèles pour les appliquer à des problématiques de traitement du langage naturel. D’où la nécessité de se former à la data science au travers d’une formation spécialisée.
Qu’est ce que le NLP ?
La NLP est une approche computationnelle de l’analyse des textes.
“Il s’agit d’une gamme de techniques informatiques à motivation théorique pour l’analyse et la représentation de textes naturels à un ou plusieurs niveaux d’analyse linguistique dans le but d’obtenir un traitement du langage similaire à l’humain pour une série de tâches ou d’applications”.
Le NLP regroupe les techniques qui utilisent des ordinateurs pour analyser, déterminer la similarité sémantique entre des mots et traduire entre les langues. Ce domaine concerne généralement les langues écrites, mais il pourrait également s’appliquer à la parole.
Dans cet article, nous aborderons les définitions et concepts nécessaires à la compréhension et méthodes nécessaires à la compréhension du NLP, les méthodes de l’analyse syntaxique ainsi que le modèle d’espace vectoriel pour le NLP au niveau du document.
Définitions et concepts
Présentons d’abord quelques définitions et concepts utilisés en NLP:
un corpus est un ensemble de documents
le lexique est un ensemble de mots utilisés dans la langue. En NLP, le lexique fait généralement référence à l’ensemble des mots uniques contenus dans le corpus
Les axes d’analyse pris en NLP sont :
la morphologie traite de la structure des mots individuels. Ainsi, les techniques dans ce domaine comprendraient des méthodes pour endiguer, attribuer la partie des balises vocales…
la syntaxe concerne la structure des phrases et les règles pour les construire. Elle est particulièrement importante car elle permet de déterminer le sens d’une phrase, également appelé sémantique.
la sémantique
Revenons quelques instants sur la syntaxe : une structure syntaxique peut être créée grâce à l’utilisation de la grammaire qui spécifie les règles de la langue. Un type de grammaire communément utilisé en NLP est la grammaire sans contexte (CFGs).
Un CFG comprend les parties suivantes :
des symboles des terminaux, qui peuvent être des mots ou de la ponctuation
des symboles non terminaux, qui peuvent être des parties de discours, de phrases…
des symboles de départ
ou encore un ensemble de règles avec un seul symbole non terminal à gauche et un ou plusieurs symboles à droite (terminaux ou non terminaux)
Les CFG ont certaines limites, mais ils peuvent s’acquitter de manière adéquate de certaines tâches de la NLP, telles que l’analyse syntaxique des phrases.
Un système de NLP devrait idéalement être capable de déterminer la structure du texte, afin de pouvoir répondre à des questions sur le sens ou la sémantique de la langue écrite. La première étape consiste à analyser les phrases en structures grammaticales. Cependant, l’analyse et la compréhension d’une langue naturelle à partir d’un domaine illimité se sont révélées extrêmement difficiles en raison de la complexité des langues naturelles, de l’ambiguïté des mots et des règles de grammaire difficiles.
Cet article fournit une introduction au NLP, qui comprend des informations sur ses principales approches.
Parmi les domaines de recherche fructueux en matière de NLP et de fouille de données textuelles, citons différentes méthodes pour la conversion de textes en données quantitatives, d’autres moyens de réduire les dimensions du texte, des techniques de visualisation des grands corpus, et des approches qui prennent en compte la dimension temporelle de certaines collections de documents.
Par conséquent, le NLP est utilisé dans une grande variété de disciplines pour résoudre de nombreux types de problèmes différents. L’analyse de texte est effectuée sur des textes allant de quelques mots saisis par l’utilisateur pour une requête Internet à de multiples documents qui doivent être résumés. La quantité et la disponibilité des données non structurées ont fortement augmenté au cours des dernières années. Cela a pris des formes telles que les blogs, les tweets et divers autres réseaux sociaux. Le NLP est idéal pour analyser ce type d’informations.
Le Machine Learning et l’analyse de texte sont fréquemment utilisés pour améliorer l’utilité d’une application.
Voici une brève liste des domaines d’application:
la recherche qui identifie des éléments spécifiques du texte. Elle peut être aussi simple que de trouver l’occurrence d’un nom dans un document ou peut impliquer l’utilisation de synonymes et d’orthographes/fausses orthographes alternatives pour trouver des entrées proches de la chaîne de recherche originale
la traduction automatique qui implique généralement la traduction d’une langue naturelle dans une autre.
des résumés : le NLP a été utilisé avec succès pour résumer des paragraphes, articles, documents ou recueils de documents
NER (Named-Entity Recognition) qui consiste à extraire du texte les noms des lieux, des personnes et des choses. Généralement, cette opération est utilisée en conjonction avec d’autres tâches du NLP, comme le traitement des requêtes
…
Les tâches du NLP utilisent fréquemment différentes techniques de Machine Learning. Une approche commune commence par la formation d’un modèle à l’exécution d’une tâche, la vérification que le modèle est correct, puis l’application du modèle à un problème.
Application du NLP
Le NLP peut nous aider dans de nombreuses tâches et ses champs d’application semblent s’élargir chaque jour. Mentionnons quelques exemples :
le NLP permet la reconnaissance et la prédiction des maladies sur la base des dossiers médicaux électroniques et de la parole du patient. Cette capacité est explorée dans des conditions de santé qui vont des maladies cardiovasculaires à la dépression et même à la schizophrénie. Par exemple, Amazon Comprehend Medical est un service qui utilise le NLP pour extraire les états pathologiques, les médicaments et les résultats des traitements à partir des notes des patients, des rapports d’essais cliniques et d’autres dossiers médicaux électroniques.
Les organisations peuvent déterminer ce que les clients disent d’un service ou d’un produit en identifiant et en extrayant des informations dans des sources telles que les réseaux sociaux. Cette analyse des sentiments peut fournir de nombreuses informations sur les choix des clients et les facteurs de décision.
Un inventeur travaillant chez IBM a mis au point un assistant cognitif qui fonctionne comme un moteur de recherche personnalisé en apprenant tout sur vous et en vous rappelant ensuite un nom, une chanson ou tout ce dont vous ne vous souvenez pas au moment où vous en avez besoin.
Le NLP est également utilisé dans les phases de recherche et de sélection de recrutement des talents, pour identifier les compétences des personnes susceptibles d’être embauchées et aussi pour repérer les prospects avant qu’ils ne deviennent actifs sur le marché du travail.
Le NLP est particulièrement en plein essor dans le secteur des soins de santé. Cette technologie améliore la prestation des soins, le diagnostic des maladies et fait baisser les coûts, tandis que les organismes de soins de santé adoptent de plus en plus les dossiers de santé électroniques. Le fait que la documentation clinique puisse être améliorée signifie que les patients peuvent être mieux compris et bénéficier de meilleurs soins de santé.