Avec l’essor des technologies numériques, la collecte et la gestion de données sont devenues des enjeux économiques stratégiques pour de nombreuses entreprises. Ces pratiques ont engendrées la naissance d’un tout nouveau secteur et de nouveaux emplois : la Data science.
IBM prévoyait une hausse de 28 % de la demande de profil Data Scientist en 2020. En effet, de nombreuses entreprises ont compris l’importance stratégique de l’exploitation de la donnée. La Data science étant au cœur de la chaîne d’exploitation de la donnée, cela explique la hausse de la demande des profils compétents dans ce domaine.
Tour d’horizon de la Data science
La Data science, ou science de la donnée, est le processus qui consiste à utiliser des algorithmes, des méthodes et des systèmes pour extraire des informations stratégiques à l’aide des données disponibles. Elle utilise l’analyse des données et le machine learning(soit l’utilisation d’algorithmes permettant à des programmes informatiques de s’améliorer automatiquement par le biais de l’expérience) pour aider les utilisateurs à faire des prévisions, à renforcer l’optimisation, ou encore à améliorer les opérations et la prise de décision.
Les équipes actuelles de professionnels de la science de la donnée sont censées répondre à de nombreuses questions. Leur entreprise exige, le plus souvent, une meilleure prévision et une optimisation basée sur des informations en temps réel appuyées par des outils spécifiques.
La science de la donnée est donc un domaine interdisciplinaire qui connaît une évolution rapide. De nombreuses entreprises ont largement adopté les méthodes de machine learning et d’intelligence artificielle (soit l’ensemble des techniques mises en œuvre en vue de réaliser des machines capables de simuler l’intelligence humaine) pour alimenter de nombreuses applications. Les systèmes et l’ingénierie des données font inévitablement partie de toutes ces applications et décisions à grande échelle axées sur les données. Cela est dû au fait que les méthodes citées plus tôt sont alimentées par des collections massives d’ensembles de données potentiellement hétérogènes et désordonnées et qui, à ce titre, doivent être gérés et manipulés dans le cadre du cycle de vie global des données d’une organisation.
Ce cycle de vie global en data science commence par la collecte de données à partir de sources pertinentes, le nettoyage et la mise en forme de celles-ci dans des formats que les outils peuvent comprendre. Au cours de la phase suivante, des méthodes statistiques et d’autres algorithmes sont utilisés pour trouver des modèles et des tendances. Les modèles sont ensuite programmés et créés pour prédire et prévoir. Enfin, les résultats sont interprétés.
Pourquoi choisir l’organisme DataScientest pour se former en Data science ?
Vous êtes maintenant convaincu de l’importance de la maîtrise de la Data science pour renforcer votre profil employable et pour aider votre entreprise.
Les formations en Data Science de l’organisme DataScientest sont conçues pour former et familiariser les professionnels avec les technologies clés dans ce domaine, dans le but de leur permettre de profiter pleinement des opportunités offertes par la science de la donnée et de devenir des acteurs actifs dans ce domaine de compétences au sein de leurs organisations.
Ces formations, co-certifiées par la Sorbonne, ont pour ambition de permettre, à toute personne souhaitant valoriser la manne de données mise actuellement à sa disposition, d’acquérir un véritable savoir-faire opérationnel et une très bonne maîtrise des techniques d’analyse de données et des outils informatiques nécessaires.
L’objectif que se fixe DataScientest est de vous sensibiliser en tant que futurs décideurs des projets data, aux fortes problématiques des données à la fois sous l’angle technique (collecte, intégration, modélisation, visualisation) et sous l’angle managérial avec une compréhension globale des enjeux.
Pourquoi choisir la formule « formation continue » chez Datascientest ?
Pendant 6 mois, vous serez formés à devenir un(e) expert(e) en data science, en maîtrisant les fondements théoriques, les bonnes pratiques de programmation et les enjeux des projets de data science.
Vous serez capable d’accompagner toutes les étapes d’un projet de data science, depuis l’analyse exploratoire et la visualisation de données à l’industrialisation d’outils d’intelligence artificielle (IA) et de machine learning, en faisant des choix éclairés d’approches, de pratiques, d’outils et de technologies, avec une vision globale : data science, data analyse, data management et machine learning. Vous pourrez cibler les secteurs extrêmement demandés de la data science.
Ce type de formation vous permettra d’acquérir les connaissances et les compétences nécessaires pour devenir data analyst, data scientist, data engineer, ou encore data manager. En effet, elles couvrent les principaux axes de la science de la donnée.
Autonomie et gestion de son temps
Que votre souhait de vous former en data science provienne d’une initiative personnelle ou qu’il soit motivé par votre entreprise, si la data science est un domaine totalement nouveau pour vous, il conviendrait de vous orienter vers le format « formation continue » de DataScientest. Effectivement, cela vous permettra de consacrer le temps qu’il vous faut pour appréhender au mieux toutes les notions enseignées. Sur une période de 6 mois, à partir de votre inscription (il y a une rentrée par mois), vous pourrez gérer votre temps comme bon vous semble, sans contrainte, que vous ayez une autre activité ou non.
Aussi, pour de nombreux salariés, il est difficile de bloquer plusieurs jours par semaine pour se former. C’est pourquoi, de plus en plus d’entreprises sollicitent des formations en ligne, à distance, pour plus d’efficacité ; vous aurez la possibilité de gérer votre temps de manière à adapter au mieux vos besoins d’apprentissage avec votre temps disponible.
Profiter de l’expertise de dizaines de data scientists
La start-up a déjà formé plus de 1500 professionnels actifs et étudiants aux métiers de Data Analysts et Data Scientists et conçu plus de 2 000 heures de cours de tout niveau, de l’acquisition de données à la mise en production.
” Notre offre répond aux besoins des entreprises, justifie Yoel Tordjman, CEO de Datascientest. Elle s’effectue surtout à distance, ce qui permet de la déployer sur différents sites à moindre coût, et de s’adapter aux disponibilités de chacun, avec néanmoins un coaching, d’abord collectif, puis par projet, dans le but d’atteindre un taux de complétion de 100 %. “
S’exercer concrètement avec un projet fil-rouge
Tout au long de votre formation et au fur et à mesure que vos compétences se développent, vous allez mener un projet de Data Science nécessitant un investissement d’environ 80 heures parallèlement à votre formation. Ce sera votre projet ! En effet, ce sera à vous de déterminer le sujet et de le présenter à nos équipes. Cela vous permettra de passer efficacement de la théorie à la pratique et de s’assurer que vous appliquez les thèmes abordés en cours. C’est aussi un projet fortement apprécié des entreprises, car il confirme vos compétences et connaissances acquises à l’issue de votre formation en Data Science. Vous ne serez jamais seul parce que nos professeurs seront toujours à vos côtés et disponibles en cas de besoin ; nous vous attribuons un tuteur pour votre projet parmi nos experts en data science.
Datascientest – Une solution de formation clé-en-main pour faciliter votre apprentissage et votre quotidien au travail
Passionné(e) par le Big Data et l’intelligence artificielle ? :
Devenez expert(e) en Data Science et intégrez le secteur le plus recherché par les entreprises. Une fois diplômé, vous pourrez commencer votre carrière en répondant parfaitement aux besoins des entreprises qui font face à une profusion et multiplication de données.
Vous souhaitez échanger avec Datascientest France autour de votre projet ?
Leader français de la formation en Data Science. Datascientest offre un apprentissage d’excellence orienté emploi pour professionnels et particuliers, avec un taux de satisfaction de 94 %.
Pour plus d’informations, n’hésitez pas à contacter DataScientest :
Le langage de programmation de Python Software Foundation est une programmation orientée objet. Lorsque les data scientists parient sur Python pour le traitement des données volumineuses, ils sont conscients qu’il existe d’autres options populaires telles que R, Java ou SAS. Toutefois, Python demeure la meilleure alternative pour ses avantages dans l’analyse du Big Data.
Pourquoi choisir Python ?
Entre R, Java ou Python pour le Big Data, choisir le dernier (en version majeure ou version mineure) est plus facile après avoir lu les 5 arguments suivants :
1. Simplicité
Python est un langage de programmation interprété connu pour faire fonctionner les programmes avec le moins de chaînes de caractères et de lignes de code. Il identifie et associe automatiquement les types de données. En outre, il est généralement facile à utiliser, ce qui prend moins de temps lors du codage. Il n’y a pas non plus de limitation pour le traitement des données.
2. Compatibilité
Hadoop est la plateforme Big Data open source la plus populaire. La prise en charge inhérente à Python, peu importe la version du langage, est une autre raison de la préférer.
3. Facilité d’apprentissage
Comparé à d’autres langages, le langage de programmation de Guido Van Rossum est facile à apprendre même pour les programmeurs moins expérimentés. C’est le langage de programmation idéal pour trois raisons. Premièrement, elle dispose de vastes ressources d’apprentissage. Deuxièmement, elle garantit un code lisible. Et troisièmement, elle s’entoure d’une grande communauté. Tout cela se traduit par une courbe d’apprentissage progressive avec l’application directe de concepts dans des programmes du monde réel. La grande communauté Python assure que si un utilisateur rencontre des problèmes de développement, il y en aura d’autres qui pourront lui prêter main-forte pour les résoudre.
4. Visualisation de données
Bien que R soit meilleur pour la visualisation des données, avec les packages récents, Python pour le Big Data a amélioré son offre sur ce domaine. Il existe désormais des API qui peuvent fournir de bons résultats.
5. Bibliothèques riches
Python dispose d’un ensemble de bibliothèques riche. Grâce à cela, il est possible de faire des mises à jour pour un large éventail de besoins en matière de science des données et d’analyse. Certains de ces modules populaires apportent à ce langage une longueur d’avance : NumPy, Pandas, Scikit-learn, PyBrain, Cython, PyMySQL et iPython.
Que sont les bibliothèques en Python ?
La polyvalence de toutes les versions de Python pour développer plusieurs applications est ce qui a poussé son usage au-delà de celui des développeurs. En effet, il a attiré l’intérêt de groupes de recherche de différentes universités du monde entier. Il leur ont permis de développer des librairies pour toutes sortes de domaines : application web, biologie, physique, mathématiques et ingénierie. Ces bibliothèques sont constituées de modules qui ont un grand nombre de fonctions, d’outils et d’algorithmes. Ils permettent d’économiser beaucoup de temps de programmation et ont une structure facile à comprendre.
Le programme Python est considéré comme le langage de programmation pour le développement de logiciels, de pages Web, d’applications de bureau ou mobiles. Mais, il est également le meilleur pour le développement d’outils scientifiques. Par conséquent, les data scientists sont destinés à aller de pair avec Python pour développer tous leurs projets sur le Big Data.
Python et la data science
La data science est chargée d’analyser, de transformer les données et d’extraire des informations utiles pour la prise de décision. Et il n’y a pas besoin d’avoir des connaissances avancées en programmation pour utiliser Python afin d’effectuer ces tâches. La programmation et la visualisation des résultats sont plus simples. Il y a peu de lignes de code en Python et ses interfaces graphiques de programmation sont conviviales.
Dans le développement d’un projet de science des données, il existe différentes tâches pour terminer ledit projet, dont les plus pertinentes sont l’extraction de données, le traitement de l’information, le développement d’algorithmes (machine learning) et l’évaluation des résultats.
Vous souhaitez devenir un professionnel de la Data mais vous ne savez pas quel métier répondra au mieux à vos attentes dans le domaine ? Dans cet article, nous allons essayer de répondre à toutes vos questions en vous présentant en détail chacun des métiers de la Data.
Le Data Scientist
Le Data Scientist est un scientifique. Il a pour but de trouver des solutions grâce à l’analyse de données. Ainsi, le Data Scientist doit trouver ou créer l’algorithme le plus intéressant pour répondre aux différents besoins de son entreprise.
Le métier de Data Scientist peut souvent faire penser qu’une connaissance très développée en mathématiques statistiques est obligatoire. Néanmoins, ce métier demande surtout d’être capable de comprendre des données et de savoir différencier un algorithme efficace et utilisable, d’un algorithme qui ne fonctionne pas correctement. Ainsi, le Data Scientist devra comparer les modèles d’analyse de données et partager ensuite son impression avec le reste de l’équipe.
Concernant les salaires, en France et selon une enquête de DataScientest sur les salaires des metiers de la data menée auprès des entreprises du CAC 40, Data Scientist peut gagner entre 35 000 et 55 000 euros par an en début de carrière. En devant senior, il peut un salaire compris entre 45 000 et 60 000 euros par an.
Le Data Engineer est comme son nom l’indique un ingénieur : il fabrique.
Ainsi, le Data Engineer se doit de réunir des données brutes et venant de nombreuses sources différentes dans une Data Warehouse centralisée : il doit donc créer et organiser les bases de données en mettant en place un pipeline pour rendre l’obtention de données et leur stockage automatique. Ensuite, le Data Engineer trie les données et les rend analysable pour les Data Scientists.
Concernant les salaires, toujours selon la même enquête de DataScientest, un Data Engineer gagne annuellement entre 35 000 et 60 000 euros et son salaire peut nettement augmenter avec les années d’expériences.
Le Data Analyst a pour mission principale d’analyser les données. Le Data Analyst possède de grandes compétences en « Data Visualization ». Il étudie notamment des bases de données nettoyée pour y trouver des connaissances qui aideront l’entreprise à prendre des décisions. Néanmoins, à la différence du Data Scientist, le Data Analyst ne formule pas lui-même les problèmes auxquels il va trouver des solutions : il se suffit à résoudre des problèmes soulignés par son entreprise notamment grâce à SQL.
Concernant le salaire, le Data Scientist a plus de compétences que le Data Analyst. Il n’est donc pas étonnant que son salaire soit supérieur. En France, toujours selon l’enquête de DataScientest, il varie annuellement entre 35 000 et 60 000 euros selon son expérience.
Le Data Manager recueille et classe les informations de l’entreprise. Ses missions principales sont de recueillir toutes les données, les organiser, les rendre compréhensible, ajouter les données manquantes, supprimer les erreurs, et enfin, sécuriser les données.
Le Data Manager peut exercer en tant que salarié de l’entreprise où il exerce ou consultant d’une entreprise extérieure à son entreprise. Concernant les salaires, un Data Manager touche mensuellement entre 2 200 et 2 600 euros bruts par mois et augmente par la suite en fonction de ses responsabilités et du domaine d’activité de son entreprise.
Le Business Analyst a un rôle très opérationnel et étudie les stratégies de l’entreprise au niveau marketing et financier. Contrairement au Data Analyst, il effectue l’analyse de l’activité de manière interne à l’entreprise.
Le Business Intelligence Manager
Le Business intelligence manager doit fouiller dans les données de l’entreprise, les trier et les analyser pour produire des guides d’aide à la prise de décision dans lequel il expose un constat, y expose ses recommandations de solutions de marketing et de data science.
Le Chief Data Officer
Le Chief Data Officer dirige la collecte des données et leur optimisation. Il décide la manière avec laquelle l’entreprise va utiliser les données qu’elle possède. Le Chief Data Officer peut être comparé à un véritable manager qui aurait certaines connaissances en Data.
Le Data Protection Officer
Le Data Protection Officer est en charge de la protection des données : il fait le lien entre la loi et la technologie. Ainsi, il donne la possibilité à son entreprise d’exploiter les données qui sont à sa disposition sans enfreindre la vie privée des utilisateurs.
Le Data Architect
Le Data Architect est, comme son nom l’indique, un architecte. Il gère la façon dont les données vont être enregistrées. Il maîtrise donc les outils du Big Data et les solutions Cloud comme l’iCloud d’Apple.
Le Data Miner
Le Data Miner extrait, trie et rend lisible les données brutes. Il intervient souvent dans les structures qui ont des sources de données extrêmement variées et qui demandent un grand nettoyage.
Le Master Data Manager
Ce métier est réservé aux personnes très qualifiées. Le Master Data Management est un terme qui désigne la gestion des données critiques. Toutes ces données sont au sein d’un seul fichier, le Master File, et permet de faciliter le partage de données entre les départements de l’entreprise.
L’Ingénieur Big Data
L’ingénieur Big Data a des tâches très variées mais se charge notamment de la valorisation des données. Il analyse en effet des grands volumes de données à l’aide de différents logiciels pour les rendre exploitable pour ensuite les classer et les mettre en avant dans des rapports détaillés. L’ingénieur Big Data est aussi en charge de la création et de la mise en place des clusters. Il doit aussi se charger de la mise en place des algorithmes et de son contrôle qualité, pour ensuite assurer la cohérence du résultat.
La Computer Vision ou vision par ordinateur est une technologie d’intelligence artificielle permettant aux machines d’imiter la vision humaine. Découvrez tout ce que vous devez savoir : définition, fonctionnement, histoire, applications, formations…
Depuis maintenant plusieurs années, nous sommes entrés dans l’ère de l’image. Nos smartphones sont équipés de caméras haute définition, et nous capturons sans cesse des photos et des vidéos que nous partageons au monde entier sur les réseaux sociaux.
Les services d’hébergement vidéo comme YouTube connaissent une popularité explosive, et des centaines d’heures de vidéo sont mises en ligne et visionnées chaque minute. Ainsi, l’internet est désormais composé aussi bien de texte que d’images.
Toutefois, s’il est relativement simple d’indexer les textes et de les explorer avec des moteurs de recherche tels que Google, la tâche est bien plus difficile en ce qui concerne les images. Pour les indexer et permettre de les parcourir, les algorithmes ont besoin de connaître leur contenu.
Pendant très longtemps, la seule façon de présenter le contenu d’une image aux ordinateurs était de renseigner sa méta-description lors de la mise en ligne. Désormais, grâce à la technologie de ” vision par ordinateur ” (Computer Vision), les machines sont en mesure de ” voir “ les images et de comprendre leur contenu.
Qu’est ce que la vision par ordinateur ?
La Computer Vision peut être décrite comme un domaine de recherche ayant pour but de permettre aux ordinateurs de voir. De façon concrète, l’idée est de transmettre à une machine des informations sur le monde réel à partir des données d’une image observée.
Pour le cerveau humain, la vision est naturelle. Même un enfant est capable de décrire le contenu d’une photo, de résumer une vidéo ou de reconnaître un visage après les avoir vus une seule fois. Le but de la vision par ordinateur est de transmettre cette capacité humaine aux ordinateurs.
Il s’agit d’un vaste champ pluridisciplinaire, pouvant être considéré comme une branche de l’intelligence artificielle et du Machine Learning. Toutefois, il est aussi possible d’utiliser des méthodes spécialisées et des algorithmes d’apprentissage général n’étant pas nécessairement liés à l’intelligence artificielle.
De nombreuses techniques en provenance de différents domaines de science et d’ingénierie peuvent être exploitées. Certaines tâches de vision peuvent être accomplies à l’aide d’une méthode statistique relativement simple, d’autres nécessiteront de vastes ensembles d’algorithmes de Machine Learning complexes.
En 1966, les pionniers de l’intelligence artificielleSeymour Papert et Marvin Minsky lance le Summer Vision Project : une initiative de deux mois, rassemblant 10 hommes dans le but de créer un ordinateur capable d’identifier les objets dans des images.
Pour atteindre cet objectif, il était nécessaire de créer un logiciel capable de reconnaître un objet à partir des pixels qui le composent. À l’époque, l’IA symbolique – ou IA basée sur les règles – était la branche prédominante de l’intelligence artificielle.
Les programmeurs informatiques devaient spécifiermanuellement les règles de détection d’objets dans les images. Or, cette approche pose problème puisque les objets dans les images peuvent apparaître sous différents angles et différents éclairages. Ils peuvent aussi être altérés par l’arrière-plan, ou obstrués par d’autres objets.
Les valeurs de pixels variaient donc fortement en fonction de nombreux facteurs, et il était tout simplement impossible de créer des règlesmanuellement pour chaque situation possible. Ce projet se heurta donc aux limites techniques de l’époque.
Quelques années plus tard, en 1979, le scientifique japonais Kunihiko Fukushima créa un système de vision par ordinateur appelé ” neocognitron “ en se basant sur les études neuroscientifiques menées sur le cortex visuel humain. Même si ce système échoua à effectuer des tâches visuelles complexes, il posa les bases de l’avancée la plus importante dans le domaine de la Computer Vision…
La révolution du Deep Learning
La Computer Vision n’est pas une nouveauté, mais ce domaine scientifique a récemment pris son envol grâce aux progrès effectués dans les technologies d’intelligence artificielle, de Deep Learninget de réseaux de neurones.
Dans les années 1980, le Français Yan LeCun crée le premier réseau de neurones convolutif : une IA inspirée par le neocognitron de Kunihiko Fukushima. Ce réseau est composé de multiples couches de neurones artificiels, des composants mathématiques imitant le fonctionnement de neurones biologiques.
Lorsqu’un réseau de neurones traite une image, chacune de ses couches extrait des caractéristiques spécifiques à partir des pixels. La première couche détectera les éléments les plus basiques, comme les bordures verticales et horizontales.
À mesure que l’on s’enfonce en profondeur dans ce réseau, les couches détectent des caractéristiques plus complexes comme les angles et les formes. Les couches finales détectent les éléments spécifiques comme les visages, les portes, les voitures. Le réseau produit enfin un résultat sous forme de tableau de valeurs numériques, représentant les probabilités qu’un objet spécifique soit découvert dans l’image.
L’invention de Yann LeCun est brillante, et a ouvert de nouvelles possibilités. Toutefois, son réseau de neurones était restreintpar d’importantes contraintes techniques. Il était nécessaire d’utiliser d’immenses volumes de données et des ressources de calcul titanesques pour le configurer et l’utiliser. Or, ces ressources n’étaient tout simplement pas disponibles à cette époque.
Dans un premier temps, les réseaux de neurones convolutifs furent donc limités à une utilisation dans les domaines tels que les banques et les services postaux pour traiter des chiffres et des lettres manuscrites sur les enveloppes et les chèques.
Il a fallu attendre 2012 pour que des chercheurs en IA de Toronto développentle réseau de neurones convolutif AlexNet et triomphent de la compétition ImageNet dédiée à la reconnaissance d’image. Ce réseau a démontré que l’explosion du volume de données et l’augmentation de puissance de calcul des ordinateurs permettaient enfin d’appliquer les ” neural networks ” à la vision par ordinateur.
Ce réseau de neurones amorça la révolution du Deep Learning : une branche du Machine Learning impliquant l’utilisation de réseaux de neurones à multiples couches. Ces avancées ont permis de réaliser des bonds de géants dans le domaine de la Computer Vision. Désormais, les machines sont même en mesure de surpasser les humains pour certaines tâches de détection et d’étiquetage d’images.
Comment fonctionne la vision par ordinateur
Les algorithmes de vision par ordinateur sont basés sur la ” reconnaissance de motifs “. Les ordinateurs sont entraînés sur de vastes quantités de données visuelles. Ils traitent les images, étiquettent les objets, et trouvent des motifs (patterns) dans ces objets.
Par exemple, si l’on nourrit une machine avec un million de photos de fleurs, elle les analysera et détectera des motifs communs à toutes les fleurs. Elle créera ensuite un modèle, et sera capable par la suite de reconnaître une fleurchaque fois qu’elle verra une image en comportant une.
Les algorithmes de vision par ordinateur reposent sur les réseaux de neurones, censés imiter le fonctionnement du cerveau humain. Or, nous ne savons pas encore exactement comment le cerveau et les yeux traitent les images. Il est donc difficile de savoir à quel point les algorithmes de Computer Vision miment ce processus biologique.
Les machines interprètent les images de façon très simple. Elles les perçoivent comme des séries de pixels, avec chacun son propre ensemble de valeurs numériques correspondant aux couleurs. Une image est donc perçue comme une grille constituée de pixels, chacun pouvant être représenté par un nombre généralement compris entre 0 et 255.
Bien évidemment, les chosesse compliquent pour les images en couleur. Les ordinateurs lisent les couleurs comme des séries de trois valeurs : rouge, vert et bleu. Là encore, l’échelle s’étend de 0 à 255. Ainsi, chaque pixel d’une image en couleur à trois valeurs que l’ordinateur doit enregistrer en plus de sa position.
Chaque valeur de couleur est stockée en 8 bits. Ce chiffre est multiplié par trois pour une image en couleurs, ce qui équivaut à 24 bits par pixel. Pour une image de 1024×768 pixels, il faut donc compter 24 bits par pixels soit presque 19 millions de bits ou 2,36 mégabytes.
Vous l’aurez compris : il faut beaucoup de mémoire pour stocker une image. L’algorithme de Computer Vision quant à lui doit parcourir un grand nombre de pixels pour chaque image. Or, il faut généralement plusieurs dizaines de milliers d’images pour entraîner un modèle de Deep Learning.
C’est la raison pour laquelle la vision par ordinateur est une discipline complexe, nécessitant une puissance de calcul et une capacité de stockage colossales pour l’entraînement des modèles. Voilà pourquoi il a fallu attendre de nombreuses années pour que l’informatique se développe et permette à la Computer Vision de prendre son envol.
Les différentes applications de Computer Vision
La vision par ordinateur englobe toutes les tâches de calcul impliquant le contenu visuel telles que les images, les vidéos ou même les icônes. Cependant, il existe de nombreuses branchesdans cette vaste discipline.
La classification d’objet consiste à entraîner un modèle sur un ensemble de données d’objets spécifiques, afin de lui apprendre à classer de nouveaux objets dans différentes catégories. L’identification d’objet quant à elle vise à entraîner un modèle à reconnaître un objet.
Parmi les applications les plus courantes de vision par ordinateur, on peut citer la reconnaissance d’écriture manuscrite. Un autre exemple est l’analyse de mouvement vidéo, permettant d’estimer la vélocité des objets dans une vidéo ou directement sur la caméra.
Dans la segmentation d’image, les algorithmes répartissent les images dans plusieurs ensembles de vues. La reconstruction de scène permet de créer un modèle 3D d’une scène à partir d’images et de vidéos.
Enfin, la restauration d’imageexploite le Machine Learning pour supprimer le ” bruit ” (grain, flou…) sur des photos. De manière générale, toute application impliquant la compréhension des pixels par un logiciel peut être associée à la Computer Vision.
Quels sont les cas d’usages de la Computer Vision ?
La Computer Vision fait partie des applications du Machine Learning que nous utilisons déjà au quotidien, parfois sans même le savoir. Par exemple, les algorithmes de Googleparcourent des cartes pour en extraire de précieuses données et identifier les noms de rues, les commerces ou les bureaux d’entreprises.
De son côté, Facebook exploite la vision par ordinateurafin d’identifier les personnes sur les photos. Sur les réseaux sociaux, elle permet aussi de détecter automatiquement le contenu problématique pour le censurer immédiatement.
Les entreprises de la technologie sont loin d’être les seules à se tourner vers cette technologie. Ainsi, le constructeur automobile Ford utilise la Computer Vision pour développer ses futurs véhicules autonomes. Ces derniers reposent sur l’analyse en temps réel de nombreux flux vidéo capturés par la voiture et ses caméras.
Il en va de même pour tous les systèmes de voitures sans pilote comme ceux de Tesla ou Nvidia. Les caméras de ces véhicules capturent des vidéos sous différents angles et s’en servent pour nourrir le logiciel de vision par ordinateur.
Ce dernier traite les images en temps réel pour identifier les bordures des routes, lire les panneaux de signalisation, détecter les autres voitures, les objets et les piétons. Ainsi, le véhicule est en mesure de conduire sur autoroute et même en agglomération, d’éviter les obstacles et de conduire les passagers jusqu’à leur destination.
La santé
Dans le domaine de la santé, la Computer Vision connaît aussi un véritable essor. La plupart des diagnostics sont basés sur le traitement d’image : lecture de radiographies, scans IRM…
Google s’est associé avec des équipes de recherche médicalepour automatiser l’analyse de ces imageries grâce au Deep Learning. D’importants progrès ont été réalisés dans ce domaine. Désormais, les IA de Computer Vision se révèlent plus performantes que les humains pour détecter certaines maladies comme la rétinopathie diabétique ou divers cancers.
Le sport
Dans le domaine du sport, la vision par ordinateur apporte une précieuse assistance. Par exemple, la Major League Baseballutilise une IA pour suivre la balle avec précision. De même, la startup londonienne Hawk-Eye déploie son système de suivi de balle dans plus de 20 sports comme le basketball, le tennis ou le football.
La reconnaissance faciale
Une autre technologie reposant sur la Computer Vision est la reconnaissance faciale. Grâce à l’IA, les caméras sont en mesure de distinguer et de reconnaître les visages. Les algorithmes détectent les caractéristiques faciales dans les images, et les comparent avec des bases de données regroupant de nombreux visages.
Cette technologie est utilisée sur des appareils grand public comme les smartphones pour authentifier l’utilisateur. Elle est aussi exploitée par les réseaux sociaux pour détecter et identifier les personnes sur les photos. De leur côté, les autorités s’en servent pour identifier les criminels dans les flux vidéo.
La réalité virtuelle et augmentée
Les nouvelles technologies de réalité virtuelle et augmentée reposent également sur la Computer Vision. C’est elle qui permet aux lunettes de réalité augmentée de détecter les objets dans le monde réelet de scanner l’environnement afin de pouvoir y disposer des objets virtuels.
Par exemple, les algorithmes peuvent permettre aux applications AR de détecter des surfaces planes comme des tables, des murs ou des sols. C’est ce qui permet de mesurer la profondeur et les dimensionsde l’environnement réel pour pouvoir y intégrer des éléments virtuels.
Les limites et problèmes de la Computer Vision
La vision par ordinateur présente encore des limites. En réalité, les algorithmes se contentent d’associer des pixels. Ils ne ” comprennent ” pas véritablement le contenu des images à la manière du cerveau humain.
Pour cause, comprendre les relations entre les personnes et les objets sur des images nécessite un sens commun et une connaissance du contexte. C’est précisément pourquoi les algorithmes chargés de modérer le contenu sur les réseaux sociaux ne peuvent faire la différence entre la pornographie et une nudité plus candide comme les photos d’allaitement ou les peintures de la Renaissance.
Alors que les humains exploitent leur connaissance du monde réel pour déchiffrer des situations inconnues, les ordinateurs en sont incapables. Ils ont encore besoin de recevoir des instructions précises, et si des éléments inconnusse présentent à eux, les algorithmes dérapent. Un véhicule autonome sera par exemple pris de cours face à un véhicule d’urgence garé de façon incongrue.
Même en entraînant une IA avec toutes les données disponibles, il est en réalité impossible de la préparer à toutes les situations possibles. La seule façon de surmonter cette limite serait de parvenir à créer une intelligence artificielle générale, à savoir une IA véritablement similaire au cerveau humain.
Comment se former à la Computer Vision ?
Si vous êtes intéressé par la Computer Vision et ses multiples applications, vous devez vous former à l’intelligence artificielle, au Machine Learning et au Deep Learning. Vous pouvez opter pour les formations DataScientest.
Le Machine Learning et le Deep Learning sont au coeur de nos formations Data Scientist et Data Analyst. Vous apprendrez à connaître et à manier les différents algorithmes et méthodes de Machine Learning, et les outils de Deep Learning comme les réseaux de neurones, les GANs, TensorFlow et Keras.
Ces formations vous permettront aussi d’acquérir toutes les compétences nécessaires pour exercer les métiers de Data Scientist et de Data Analyst. À travers les différents modules, vous pourrez devenir expert en programmation, en Big Data et en visualisation de données.
Nos différentes formations adoptent une approche innovante de Blended Learning, alliant le présentiel au distanciel pour profiter du meilleur des deux mondes. Elles peuvent être effectuées en Formation Continue, ou en BootCamp.
Pour le financement, ces parcours sont éligibles au CPF et peuvent être financés par Pôle Emploi via l’AIF. À l’issue du cursus, les apprenants reçoivent un diplôme certifié par l’Université de la Sorbonne. Parmi nos alumnis, 93% trouvent un emploi immédiatementaprès l’obtention du diplôme. N’attendez plus, et découvrez nos formations.
En mars 2020 l’Institut Montaigne diffusait une étude sur le contrôle des biais. La semaine dernière, c’est un groupement d’environ une soixantaine de chercheurs d’institutions, d’entreprises américaines et européennes spécialisés autour de l’intelligence artificielle ou IA (École Normale Supérieure de Paris, Alan Turing Institute, Cambridge, Stanford, Oxford, Google, Berkeley, Intel, etc.) qui a publié un rapport appelant au contrôle de l’éthique des IA.
Depuis quelques temps déjà, ce besoin d’encadrement est régulièrement évoqué, voir notre article « Ethique ou Big Data ». De nombreux rapports ont déjà été édités explicitant les différents problèmes éthiques de l’IA. Dans ces deux derniers rapports sont encore pointés ces mêmes problèmes, comme le contrôle des biais, la mise en place de bonnes pratiques communes mais aussi le manque de soutien financiers des politiques publiques pour financer la recherche à ce sujet.
Afin d’assurer un développement de l’IA efficient tout en respectant les droits fondamentaux de chacun est devenu une urgence, la crise sanitaire et les différentes problématiques que l’utilisation des données a pu engendrer au niveau éthique va, espérons-le, certainement accélérer cet encadrement des pratiques de l’IA.
Dans son étude l’Institut Montaigne incite plus à la prévention et à la sensibilisation qu’à la régulation et la sanction.
Les 4 recommandations qui ont été mises en avant par l’Institut sont les suivantes :
Tester la présence de biais dans les algorithmes comme l’on teste les effets secondaires des médicaments.
Promouvoir une équité active plutôt que d’espérer l’équité en ne mesurant pas la diversité.
Être plus exigeant pour les algorithmes ayant un fort impact sur les personnes (droit fondamentaux, sécurité, accès aux services essentiels)
Assurer la diversité des équipes de conception et de déploiement des algorithmes
L’institut préconise également l’émergence de labels qui garantissent la qualité des données utilisées et de l’organisation qui développe l’algorithme, l’existence de procédures de contrôle ou encore l’audibilité de l’algorithme, une capacité d’audit et de contrôle de certaines exigences pourrait être confiée à une tierce partie ou à l’État.
Dans le rapport publié la semaine dernière par le groupement de divers spécialistes internationaux de IA, on retrouve quasi la même préconisation parmi les 10 préconisées :
« Les organismes de normalisation doivent travailler avec les universités et l’industrie pour développer des exigences d’audit pour les applications critiques des algorithmes. »
Ce rapport préconise également d’autres pistes comme la mise en place de « bias bounty », d’une mutualisation des travaux et des outils entre organisations, en effet à l’heure actuelle chaque entreprise, université, s’applique des normes éthiques qui lui sont propres ce qui peut entrainer de nombreuses dérives.
Au niveau de l’état français, ce besoin d’encadrement est bien pris en compte puisqu’un budget de 30 M€ a été alloué à la certification de l’IA pour éviter les biais liés aux algorithmes (évaluation éthique des algorithmes, consolidation des algorithmes grâce à un dispositif de certificabilité) comme évoqué dans notre article « État et IA: une union en bonne voie? »
Déjà depuis 2018, conscients de la nécessité d’une coopération et d’une coordination à l’échelle internationale pour exploiter le plein potentiel de l’IA ,le Canada et la France dans le cadre du G7, travaillent ensemble aux côtés de la communauté internationale à la création d’un groupe international d’experts sur l’intelligence artificielle (G2IAou IPAI, pour international panel on artificial intelligence ) , sur le même modèle que le GIEC, pour favoriser la collaboration et la coordination internationale.
Ce groupement d’experts devra s’engager à respecter les valeurs communes suivantes lors du développement, de l’adoption et de l’utilisation de l’IA :
Promouvoir et protéger une approche de l’IA à la fois éthique et centrée sur l’humain, fondée sur les droits de l’homme ;
Promouvoir une approche multipartite de l’IA ;
Stimuler l’innovation, la croissance et le bien-être à travers l’IA ;
Mettre les travaux sur l’IA en adéquation avec les principes de développement durable et la réalisation du Programme développement durable à horizon 2030
Renforcer la diversité et l’inclusion à travers l’IA ;
Favoriser la transparence et l’ouverture des systèmes d’IA ;
Favoriser la confiance et la redevabilité en matière d’IA ;
Promouvoir et protéger les valeurs, les procédures et les institutions démocratiques ;
Combler les fractures numériques ;
Promouvoir la coopération scientifique internationale dans le domaine de l’IA.
Le 22 mai 2019 c’étaient les 36 pays membres de l’OCDE, ainsi que l’Argentine, le Brésil, la Colombie, le Costa Rica, le Pérou et la Roumanie qui ont adhéré aux Principes de l’OCDE sur l’intelligence artificielle. Principes élaborés avec le concours d’un groupe de plus de 50 experts de tous horizons – administrations, milieux universitaires, entreprises, société civile, instances internationales, communauté technique et organisations syndicales.
La conclusion évidente, à la vue de ces nombreux rapports émanant d’experts, de principes sur les bons usages de l’IA prescrits par diverses institutions, ou de la création du G2IA est que l’ensemble des acteurs économiques a un besoin urgent de repères communs afin de pouvoir se saisir pleinement et en toute légalité du potentiel de l’IA. La société numérique de demain a besoin de ce cadre pour pouvoir grandir et se développer sur des bases saines.
Après avoir passé ces dernières semaines à acquérir de nouvelles connaissances en data science et être monté en compétences, vous avez obtenu votre diplôme en data science ! Congrats ! Python est devenu votre ami et vous êtes prêts à décortiquer des données pour leur donner un sens et apporter votre expertise au sein d’une entreprise. Maintenant il n’y a plus qu’à trouver l’entreprise qui aura la chance de vous accueillir. Pour ce faire, vous devez être en mesure de rédiger le CV data science parfait.
Tout le monde le sait aujourd’hui, le temps accordé à la lecture d’un CV est très court (5 à 10 secondes selon certains). A la décharge des recruteurs, pour certains postes il y a souvent des centaines de postulants. Quand vous recevez une telle masse d’informations, pas évident de faire le tri.
Donc vous devez capter immédiatement l’attention du recruteur et vous démarquer sans en faire trop, cependant il y a quelques erreurs à ne pas faire.
Nous avons concocté une petite liste de conseils pour vous aider à mettre en valeur vos compétences en data science et surtout ce qui fait de vous LA personne dont une entreprise ne pourra se passer.
Ca peut paraître bête mais pensez à utiliser la même police, sobre de préférence (Calibri, Arial, etc.) surtout pas de police type Comic Sans MS.
Mettez en gras les éléments importants, l’alignement, pensez aux couleurs aussi, au maximum 3. Alors attention quand on parle de couleur, une couleur doit être utilisée avec parcimonie dans un CV. Les CV trop graphiques et originaux sont déconseillés en data science.
Toute la difficulté de l’exercice est là justement, trouver le juste milieu entre le niveau d’informations à fournir (un CV trop lourd fait généralement fuir) et faire en sorte que votre CV ressorte du lot.
Être sobre et précis !
Maintenant, des tas de template de CV sont à disposition sur le net, si vous êtes plus à l’aise avec Python qu’avec Word, n’hésitez pas.
Il y a des éléments indispensables qui doivent apparaître dans votre CV, pour que ces éléments ressortent il est préférable de l’organiser en sections ou blocs.
Et le petit défi, il faut que l’ensemble de ces informations rentre dans 1 page, au-delà il y a un risque de perdre l’attention du recruteur.
Le but d’un CV est de présenter rapidement votre parcours, votre évolution professionnelle, c’est comme le teaser d’un film, le film étant votre futur entretien avec le recruteur.
Dans un teaser, on voit les moments forts du film, les éléments mis en avant donnent envie d’aller voir le film. De plus, un teaser de film peut être différent selon le public visé, d’un pays à l’autre, parfois ce n’est pas la même version. Et bien pour votre CV c’est la même chose, votre public ce sont les recruteurs et ils sont tous différents vis à vis de leur besoin qui est l’annonce à laquelle vous postulez, il faut que le teaser corresponde à l’attente de votre public.
Attention au titre de votre CV, il doit être en adéquation avec l’annonce à laquelle vous répondez. En effet un CV doit être adapté à l’offre, il faut personnaliser votre CV en fonction des éléments qui sont évoqués dans l’annonce. Repérez quelques mots clefs dans l’annonce et utilisez-les dans votre CV. Certes c’est un petit travail supplémentaire mais le recruteur appréciera de lire un CV qui fait écho à son annonce. C’est ce genre de petit détail qui fera que votre CV se détachera du lot
L’accroche d’intro, c’est là qu’il faut placer les fameux soft skills. Les postes en data science nécessitent des compétences techniques mais demandent également de posséder de nombreuses compétences transversales. La mission d’un expert en data science n’est pas seulement de faire des calculs et d’analyser des données mais aussi de mettre en pratique sa capacité à communiquer ces résultats afin de résoudre une problématique particulière.
On attendra donc d’un spécialiste des sciences des données un esprit d’analyse et de synthèse, une curiosité intellectuelle et une facilité à comprendre un secteur, qu’il puisse travailler en équipe ou gérer une équipe (le leadership), son aisance à restituer les résultats de manière claire et efficiente (communication), sa rigueur et sa méthodologie.
Votre état civil
Bien évidemment nom, prénom, adresse, numéro de téléphone, votre adresse mail professionnel (par exemple “nom-prénom@XXX” et pas “darkdragon198xd@xxx” ou “jsuioufdecode@xxx”, etc. C’est du vécu).
La photo c’est comme vous voulez, ne vous sentez pas obligé d’en mettre une. Mais si vous en mettez une, veillez à ce qu’elle soit professionnelle. Il est préférable d’avoir un CV sans photo qu’un CV avec une photo décalée.
Vous pouvez aussi rajouter le lien (cliquable) de votre profil LinkedIn, uniquement si celui-ci est complet avec vos expériences et compétences renseignées.
Le must si possible : un lien Github. Vous postulez pour des postes en data science, donc la plupart des recruteurs seront plus que ravis de jeter un coup d’œil à vos réalisations. Et bien évidemment lorsqu’un recruteur clique sur votre GitHub, il doit trouver un compte actif avec des projets de science des données. Mais nous reviendrons plus tard sur cet élément qui peut être déterminant pour un recruteur.
La formation
Cette section reprend les études suivies et les diplômes obtenus durant votre scolarité. Mentionnez également dans cette partie vos certifications acquises en formation continue. Les langues maîtrisées et leur niveau (bilingue, courant, opérationnel, scolaire), ou mention des éventuels séjours à l’étranger, l’idéal étant d’avoir une certification en langue reconnue. Une très bonne maîtrise de l’anglais est demandée pour les postes en data science, votre capacité à communiquer avec divers interlocuteurs à travers le monde est fortement appréciée des grands groupes.
Cette section correspond à la liste des compétences techniques que vous maîtrisez.
Les soft skills ayant été spécifiés dans votre accroche, pas besoin de les repréciser ici !
Petit conseil, concentrez vous sur les compétences techniques qui sont mises en avant dans l’annonce. Personne ne mobilise l’ensemble de ses compétences sur un projet, selon la problématique vous allez mobiliser différentes compétences. L’objectif de cette section est de donner au recruteur une idée de vos capacités.
Surtout, encore une fois, n’en faites pas trop, si vous mentionnez quelque chose sur votre CV, vous devez être en mesure de répondre au recruteur si celui-ci veut s’assurer que vous possédez bien les bases. Si vous avez suivi un MOOC sur R, mais que vous n’avez jamais codé en R, abstenez-vous de mettre R comme une de vos compétence. Ne mentionnez que les compétences dont vous pouvez parler en véritable professionnel.
Attention, la notion d’étoiles ou de notes pour illustrer un niveau n’est pas forcément très judicieuse puisque l’échelle d’étalonnage de cette note, c’est la vôtre, donc pas forcément objective. Il vaut mieux rester simple et ne pas vendre du rêve aux recruteurs.
Toutes vos expériences professionnelles ou bénévoles pertinentes
Indiquez clairement le poste exercé (le mettre en gras pour qu’il soit plus visible) et le nom de l’entreprise, le secteur d’activité. Et dans l’ordre chronologique bien sûr, du plus récent au plus ancien. Il faut qu’on voit votre montée en compétences au fur et à mesure des postes, qu’on sente votre évolution. Dans cette même section vous pouvez créer une ligne spéciale ou vous spécifiez vos participations à des data challenges, des hackathons IA. Cela montre aux recruteurs que vous avez un esprit de compétition et que vous cherchez à améliorer en permanence vos compétences et vos connaissances dans votre domaine.
Vos réalisations en entreprises / les projets menés
Il faut faire la distinction entre une expérience professionnelle et vos projets menés. Vous avez réalisé des projets en science des données durant votre parcours de formation, mais également lors de vos expériences en entreprise, ou alors dans une démarche totalement personnelle, vous avez appliqué vos compétences techniques (hard skills) et vos compétences sociales (soft skills) et avez su les mobiliser pour résoudre une problématique. C’est dans cette section que les recruteurs pourront déterminer si effectivement votre profil correspond à leurs attentes et que vous êtes LA personne à recruter.
Chaque projet doit indiquer la problématique et sa solution, et pensez verbe d’action lors de la rédaction ! Le tout doit tenir en quelques lignes, c’est à notre sens l’exercice qui demande le plus d’attention car c’est là que les recruteurs vont focaliser leur regard. Lorsque vous décrivez un projet, soyez aussi précis que possible sur les compétences, les outils et les technologies que vous avez utilisés, comment vous avez créé le projet, n’oubliez pas de spécifier le langage de codage, les bibliothèques que vous avez utilisées, etc.
Par exemple :
Projet xxxxxx
Brève description de la problématique
Solution
Mention de travail d’équipe éventuellement
Les outils et les méthodes utilisées
Cette section est stratégique, elle doit inclure des projets d’analyse de données, des projets d’apprentissage automatique et éventuellement les articles scientifiques publiés (avec leur lien) ou des didacticiels de codage. C’est LA section ou vous pouvez vous démarquer ! En spécifiant des projets en science des données menés vous démontrez que vous avez les compétences techniques mais également les compétences transverses indispensables à tout spécialiste de la data science. Les recruteurs ne retiendront pas votre candidature pour quelque chose que vous n’avez jamais fait auparavant, c’est une règle fondamentale dans n’importe quel secteur, et la data science ne fait pas exception à la règle.
Selon votre expérience (jeune diplômé ou en reconversion) et si vous avez mené beaucoup de projets, faites un choix et mettez en avant ceux qui sont en lien avec l’offre pour laquelle vous postulez.
Tips spécial Doctorant
Si vous êtes à la recherche de votre premier emploi dans en data science, il peut être difficile de démontrer l’étendue de vos compétences et l’adéquation de celles-ci avec l’annonce à laquelle vous postulez.
Mais il existe plusieurs façons de démontrer vos compétences, en plus de la liste de vos projets et publications en sciences des données qui apparaissent dans votre CV. Lorsque l’on a mené de nombreux projets en data science ou même publié des articles, il peut être très utile de partager un lien GitHub contenant les projets de data science les plus intéressants que vous ayez menés. Nous vous invitons à consulter l’article dédié comment créer un portfolio GitHub.
Un portfolio GitHub doit contenir 3 à 5 projets à minima, encore une fois l’objectif est de démontrer vos compétences donc il faut mettre en avant les projets en lien avec l’annonce. Ces projets seront certainement évoqués si vous obtenez un entretien, là il faudra prouver que vous maitrisez votre sujet sur le bout des doigts.
Les centres d’intérêts et loisirs
Là, vous pouvez également vous distinguer mais toujours sans en faire trop. Si vous faites de la compétition sportive, mentionnez-le, ça prouvera votre esprit compétitif. Artiste à vos heures, n’hésitez pas non plus, cela démontre une créativité certaine. Vous faites du bénévolat n’hésitez pas à le mentionner, cela démontre l’engagement.
Ça y est, vous en êtes venus à bout, vous avez réussi à tout intégrer en 1 seule page ! Vos compétences sont mises en avant, votre expérience professionnelle apparaît chronologiquement, les projets sont décrits de manière succincte et claire. Surtout assurez-vous de la cohérence de votre CV/teaser par rapport à l’annonce que vous avez ciblée. Avez-vous bien compris les attentes de votre public (le descriptif de l’annonce), les moments forts de votre teaser sont-ils en cohérence avec les attentes du public, l’ensemble est-il aéré mais suffisamment complet pour donner l’envie d’aller plus loin.
A force d’avoir la tête dedans, des fois il y a des petits détails qui peuvent nous échapper, n’hésitez pas à solliciter un de vos proches pour vous relire afin de vous assurez que vous n’avez pas oublié une petite coquille.
Une fois sûr de vous, enregistrez votre CV en format pdf pour éviter tout problème de lecture, assurez vous également que les liens insérés dans votre CV soient actifs.
Maintenant, il n’y a plus qu’à rédiger la lettre de motivation, un autre exercice qu’il ne faut pas négliger, pour préparer cette autre étape, vous trouverez tous nos conseils dans notre prochain article dédié à ce sujet.
L’apprentissage supervisé, dans le contexte de l’intelligence artificielle, est la méthode d’apprentissage la plus utilisée en Machine Learning et en Deep Learning. L’apprentissage supervisé consiste à surveiller l’apprentissage de la machine en lui présentant des exemples de ce qu’elle doit effectuer. Ses utilisations sont nombreuses : reconnaissance vocale, intelligence artificiel
le, classifications, etc. Ainsi, la régression linéaire fait partie d’une des techniques d’apprentissage supervisé la plus utilisée dans la prédiction d’une valeur continue. Aussi, la grande majorité des problèmes de Machine Learning et de Deep Learning utilisent l’apprentissage supervisé : il est donc primordial de comprendre correctement le fonctionnement de cette méthode.
Comment fonctionne un apprentissage supervisé ?
Le but de l’apprentissage automatique est de créer des algorithmes aptes à recevoir des ensembles de données et à réaliser une analyse statistique pour prédire un résultat.
Si on appelle ça un apprentissage supervisé, c’est parce que le processus d’un algorithme tiré du Training Set (ensembles de données) peut être considéré comme un enseignant qui surveille le processus d’apprentissage. Nous connaissons les bonnes réponses, l’algorithme effectue des prédictions sur les réponses et est ensuite corrigé par l’enseignant. L’apprentissage cesse quand l’algorithme atteint le niveau attendu pour être efficient.
Il consiste en des variables d’entrée X et une variable de sortie Y. L’algorithme a pour but d’apprendre la fonction de l’entrée jusqu’à la sortie.
Y = f (X)
Les étapes de l’apprentissage automatique sont :
La collecte des données et leur labellisation
Le nettoyage des données pour identifier de potentielles erreurs ou manquement
Le prétraitement des données (identification des variables explicatives notamment)
Instanciation des modèles (modèle de régression ou de classification par exemple).
Entraînement des modèles
Validation du modèle
Ainsi et comme le montre la formule Y = f (X), le modèle d’apprentissage supervisé est très efficace pour étudier des relations linéaires mais il reste incapable de performer quand il y a des relations plus complexes qu’une linéarité entre les variables.
Apprentissage supervisé ou non supervisé ?
L’apprentissage non supervisé correspond au fait de n’utiliser que des données d’entrée (X) et aucune variable de sortie Y correspondante. Le but de l’apprentissage non supervisé est de modéliser la structure des données afin d’en apprendre plus sur les données et à la différence de l’apprentissage supervisé, il n’y a pas de bonne réponse ni d’enseignant. Les algorithmes sont laissés à leurs propres processus pour étudier et choisir la structure des données qui soit intéressante.
L’apprentissage automatique présente des atouts que les apprentissages non supervisés n’ont pas, mais il rencontre aussi des difficultés. En effet, l’apprentissage supervisé est plus apte à prendre des décisions auxquelles les humains peuvent s’identifier car les données sont elles-mêmes fournies par l’humain. Néanmoins, les apprentissages supervisés rencontrent plus de difficultés à traiter les données qui s’ajoutent après l’apprentissage. En effet, si un système connaît les groupes chiens et chats et reçoit une photographie de souris, il devra la placer dans l’un ou l’autre de ces deux groupes alors qu’elle n’y appartient pas. Au contraire, si le système avait suivi un apprentissage non supervisé, il ne serait pas capable d’identifier que c’est une souris mais il serait capable de le définir comme n’appartenant à aucune des 2 catégories chiens et chats.
Considérons le problème classique de la fidélisation des clients, nous constatons que nous pouvons l’aborder de différentes manières. Une entreprise veut segmenter ses clients. Cependant, quelle est la stratégie la plus appropriée ? Est-il préférable de traiter cela comme un problème de classification, de regroupement ou même de régression ? L’indice clé va nous donner la deuxième question.
Si l’entreprise se demande : « Mes clients se regroupent-ils naturellement d’une manière ou d’une autre ? », il n’y a pas à définir de cible pour le regroupement. En revanche, si elle pose la question autrement : « Pouvons-nous identifier des groupes de clients ayant une forte probabilité de se désabonner dès la fin de leur contrat ? », l’objectif sera bien défini. Par conséquent, elle prendra des mesures en fonction de la réponse à la question qui suit : « Le client va-t-il se désabonner ? ».
Dans le premier cas, nous avons affaire à un exemple d’apprentissage non supervisé, tandis que le second est un exemple d’apprentissage supervisé.
L’apprentissage supervisé chez DataScientest
Considérant l’efficacité et l’importance de l’apprentissage supervisé, DataScientestle place parmi les connaissances à valider aux cours de ses formations. Notamment au sein de la formation de data analyst et dans le module de Machine Learning de 75h, il vous sera demandé d’apprendre à identifier les problèmes de Machine Learning non supervisés, et apprendre à utiliser des méthodes d’apprentissage supervisé par des problèmes de régression. De même, dans la formation de data management, dans le module Data Literacy, nous apprendrons à identifier quelle méthode de Machine Learning utiliser selon le type de métier. Enfin, dans la formation de data scientist, le module de Machine Learning de 75h se verra attribuer une partie conséquente sur le sujet des apprentissages supervisés et non supervisés, leurs mises en place et l’identification de leurs problèmes.
Devenir Data Scientist en ligne, mythe ou réalité ? Grâce à l’expérience d’apprenants, nous apportons des réponses à vos questionnements ! Bienvenue dans le premier épisode d’une série d’articles autour de la formation data en ligne !
Construire des modèles, apporter du sens aux données de l’entreprise et les rendre lisibles pour le commun des mortels : telles sont les missions quotidiennes d’un Data Scientist. Si vous aussi souhaitez manier la data comme un maître et apporter votre valeur ajoutée à l’entreprise. Restez avec nous, on vous explique comment faire !
Pourquoi devenir Data Scientist ?
Le métier de Data Scientist est un métier d’avenir. D’ailleurs, selon le Harvard Business c’est le “métier le plus sexy du 21e siècle”. Ce n’est pas nous qui le disons, c’est Harvard et généralement ils savent de quoi ils parlent 😉 ! En effet, avec les nouveaux besoins issus des données massives de notre époque, plus communément connue sous l’ère du Big Data, c’est un métier qui est extrêmement recherché. Les géants comme Google, Amazon, Facebook en recrutent énormément depuis quelques années.
Souvent, le métier de data scientist se concentre sur la mise en place d’algorithmes basés sur la donnée pour apporter des solutions à des problématiques aussi diverses que variées. Que ce soit de la détection d’anomalies, de la prévision ou de la gestion de risque, le Data Scientist est capable de répondre à ces enjeux grâce à son fer de lance : ses modèles.
Thibault, un Data Scientist ayant suivi une formation en ligne, a réussi à trouver une image parfaite pour décrire les outils du Data Scientist :
« les modèles pour un Data Scientist sont ce que l’arc et les flèches sont pour Robin des bois »
Si cette image vous met l’eau à la bouche, je vous invite à découvrir plus en détails la formation adéquate pour devenir Data Scientist. De nombreux organismes de formation proposent des formations dont DataScientest, l’entreprise leader de la formation en Data Science.
Effectivement, c’est tout à fait possible voire encouragé ! On pense que ce type de formation peut être extrêmement bénéfique pour l’expérience personnelle de l’apprenant. Après tout, chaque Data Scientist qui se respecte se doit d’être à l’aise sur un ordinateur 😉 !
L’avantage principal d’une formation en ligne est « la flexibilité personnalisable » selon Marie, issue d’une formation intensive de 11 semaines à l’issue de laquelle elle a décroché une certification Data Scientist reconnue par la Sorbonne :
« La formation Data Scientist en ligne permet d’avancer à son rythme et en fonction de ses contraintes tout en bénéficiant d’un accompagnement de bout à bout tout . »
La mise en place d’une plateforme d’apprentissage pour du “learning by doing”, permet de suivre votre évolution et votre parcours.
Par ailleurs, Chad, un apprenant international qui a suivi une formation en anglais, partage des éléments pour rassurer les personnes qui auraient encore des hésitations. Il faisait référence par exemple, au matériel informatique utilisé se former et se lancer dans la formation de Data Scientist en ligne :
« At first, I thought that I needed a specific material like a powerful laptop to join the training but I was wrong ! »
Yes, he was wrong car grâce aux outils technologiques tels qu’une plateforme Full SaaS par exemple, vous n’avez plus besoin d’avoir un ordinateur spécifique mais juste un bon accès à internet et le tour est joué.
D’autres prérequis évoqués par Sarah sont « la communication et l’autodiscipline », qui lorsqu’ils sont absents peuvent à priori mettre à mal l’apprentissage en ligne. Encore une fois, des solutions existent pour pallier ces lacunes. En effet, DataScientest par exemple propose un accompagnement à tout instant :
« Grâce à un accès h24 à la plateforme, le support et la présence continuelle de la part de nos formateurs, je me suis sentie accompagnée et remotivée dès que j’avais des coups de mou. »
Bref, je vous ai expliqué en quelques mots en quoi consistait une formation Data Scientist en ligne, Si vous souhaitez plus d’informations concernant ce métier et la formation adéquate, n’hésitez pas à vous orienter vers un de nos organismes partenaires !
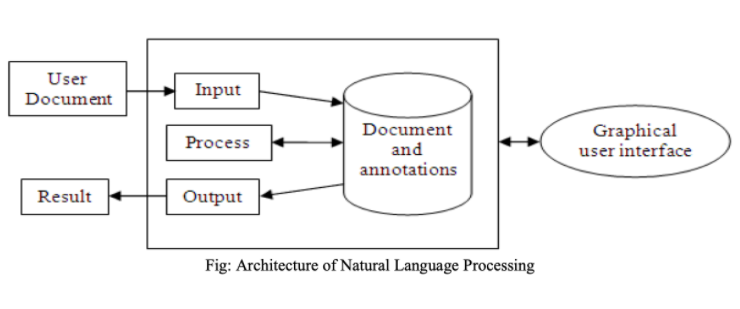
C’est seulement il y a 40 ans que l’objectif de doter les ordinateurs de la capacité de comprendre le langage naturel au sens de courant a commencé. Cet objectif de compréhension du langage naturel par les ordinateurs – plus communément appelé traitement du langage naturel ou “natural language processing” en anglais (NLP)est le sujet de cet article.
La maitrise du NLP permet d’accéder à des opportunités professionnelles dans le secteur de la data science. Seul un data scientist qui maitrise les techniques de machine learning et deep learning sera capable d’utiliser ces modèles pour les appliquer à des problématiques de traitement du langage naturel. D’où la nécessité de se former à la data science au travers d’une formation spécialisée.
Qu’est ce que le NLP ?
La NLP est une approche computationnelle de l’analyse des textes.
“Il s’agit d’une gamme de techniques informatiques à motivation théorique pour l’analyse et la représentation de textes naturels à un ou plusieurs niveaux d’analyse linguistique dans le but d’obtenir un traitement du langage similaire à l’humain pour une série de tâches ou d’applications”.
Le NLP regroupe les techniques qui utilisent des ordinateurs pour analyser, déterminer la similarité sémantique entre des mots et traduire entre les langues. Ce domaine concerne généralement les langues écrites, mais il pourrait également s’appliquer à la parole.
Dans cet article, nous aborderons les définitions et concepts nécessaires à la compréhension et méthodes nécessaires à la compréhension du NLP, les méthodes de l’analyse syntaxique ainsi que le modèle d’espace vectoriel pour le NLP au niveau du document.
Définitions et concepts
Présentons d’abord quelques définitions et concepts utilisés en NLP:
un corpus est un ensemble de documents
le lexique est un ensemble de mots utilisés dans la langue. En NLP, le lexique fait généralement référence à l’ensemble des mots uniques contenus dans le corpus
Les axes d’analyse pris en NLP sont :
la morphologie traite de la structure des mots individuels. Ainsi, les techniques dans ce domaine comprendraient des méthodes pour endiguer, attribuer la partie des balises vocales…
la syntaxe concerne la structure des phrases et les règles pour les construire. Elle est particulièrement importante car elle permet de déterminer le sens d’une phrase, également appelé sémantique.
la sémantique
Revenons quelques instants sur la syntaxe : une structure syntaxique peut être créée grâce à l’utilisation de la grammaire qui spécifie les règles de la langue. Un type de grammaire communément utilisé en NLP est la grammaire sans contexte (CFGs).
Un CFG comprend les parties suivantes :
des symboles des terminaux, qui peuvent être des mots ou de la ponctuation
des symboles non terminaux, qui peuvent être des parties de discours, de phrases…
des symboles de départ
ou encore un ensemble de règles avec un seul symbole non terminal à gauche et un ou plusieurs symboles à droite (terminaux ou non terminaux)
Les CFG ont certaines limites, mais ils peuvent s’acquitter de manière adéquate de certaines tâches de la NLP, telles que l’analyse syntaxique des phrases.
Un système de NLP devrait idéalement être capable de déterminer la structure du texte, afin de pouvoir répondre à des questions sur le sens ou la sémantique de la langue écrite. La première étape consiste à analyser les phrases en structures grammaticales. Cependant, l’analyse et la compréhension d’une langue naturelle à partir d’un domaine illimité se sont révélées extrêmement difficiles en raison de la complexité des langues naturelles, de l’ambiguïté des mots et des règles de grammaire difficiles.
Cet article fournit une introduction au NLP, qui comprend des informations sur ses principales approches.
Parmi les domaines de recherche fructueux en matière de NLP et de fouille de données textuelles, citons différentes méthodes pour la conversion de textes en données quantitatives, d’autres moyens de réduire les dimensions du texte, des techniques de visualisation des grands corpus, et des approches qui prennent en compte la dimension temporelle de certaines collections de documents.
Par conséquent, le NLP est utilisé dans une grande variété de disciplines pour résoudre de nombreux types de problèmes différents. L’analyse de texte est effectuée sur des textes allant de quelques mots saisis par l’utilisateur pour une requête Internet à de multiples documents qui doivent être résumés. La quantité et la disponibilité des données non structurées ont fortement augmenté au cours des dernières années. Cela a pris des formes telles que les blogs, les tweets et divers autres réseaux sociaux. Le NLP est idéal pour analyser ce type d’informations.
Le Machine Learning et l’analyse de texte sont fréquemment utilisés pour améliorer l’utilité d’une application.
Voici une brève liste des domaines d’application:
la recherche qui identifie des éléments spécifiques du texte. Elle peut être aussi simple que de trouver l’occurrence d’un nom dans un document ou peut impliquer l’utilisation de synonymes et d’orthographes/fausses orthographes alternatives pour trouver des entrées proches de la chaîne de recherche originale
la traduction automatique qui implique généralement la traduction d’une langue naturelle dans une autre.
des résumés : le NLP a été utilisé avec succès pour résumer des paragraphes, articles, documents ou recueils de documents
NER (Named-Entity Recognition) qui consiste à extraire du texte les noms des lieux, des personnes et des choses. Généralement, cette opération est utilisée en conjonction avec d’autres tâches du NLP, comme le traitement des requêtes
…
Les tâches du NLP utilisent fréquemment différentes techniques de Machine Learning. Une approche commune commence par la formation d’un modèle à l’exécution d’une tâche, la vérification que le modèle est correct, puis l’application du modèle à un problème.
Application du NLP
Le NLP peut nous aider dans de nombreuses tâches et ses champs d’application semblent s’élargir chaque jour. Mentionnons quelques exemples :
le NLP permet la reconnaissance et la prédiction des maladies sur la base des dossiers médicaux électroniques et de la parole du patient. Cette capacité est explorée dans des conditions de santé qui vont des maladies cardiovasculaires à la dépression et même à la schizophrénie. Par exemple, Amazon Comprehend Medical est un service qui utilise le NLP pour extraire les états pathologiques, les médicaments et les résultats des traitements à partir des notes des patients, des rapports d’essais cliniques et d’autres dossiers médicaux électroniques.
Les organisations peuvent déterminer ce que les clients disent d’un service ou d’un produit en identifiant et en extrayant des informations dans des sources telles que les réseaux sociaux. Cette analyse des sentiments peut fournir de nombreuses informations sur les choix des clients et les facteurs de décision.
Un inventeur travaillant chez IBM a mis au point un assistant cognitif qui fonctionne comme un moteur de recherche personnalisé en apprenant tout sur vous et en vous rappelant ensuite un nom, une chanson ou tout ce dont vous ne vous souvenez pas au moment où vous en avez besoin.
Le NLP est également utilisé dans les phases de recherche et de sélection de recrutement des talents, pour identifier les compétences des personnes susceptibles d’être embauchées et aussi pour repérer les prospects avant qu’ils ne deviennent actifs sur le marché du travail.
Le NLP est particulièrement en plein essor dans le secteur des soins de santé. Cette technologie améliore la prestation des soins, le diagnostic des maladies et fait baisser les coûts, tandis que les organismes de soins de santé adoptent de plus en plus les dossiers de santé électroniques. Le fait que la documentation clinique puisse être améliorée signifie que les patients peuvent être mieux compris et bénéficier de meilleurs soins de santé.
Nous entendons tous parler du terme « Machine Learning », qui peut se décomposer en trois grandes catégories :
L’apprentissage supervisé
L’apprentissage non supervisé
L’apprentissage par renforcement
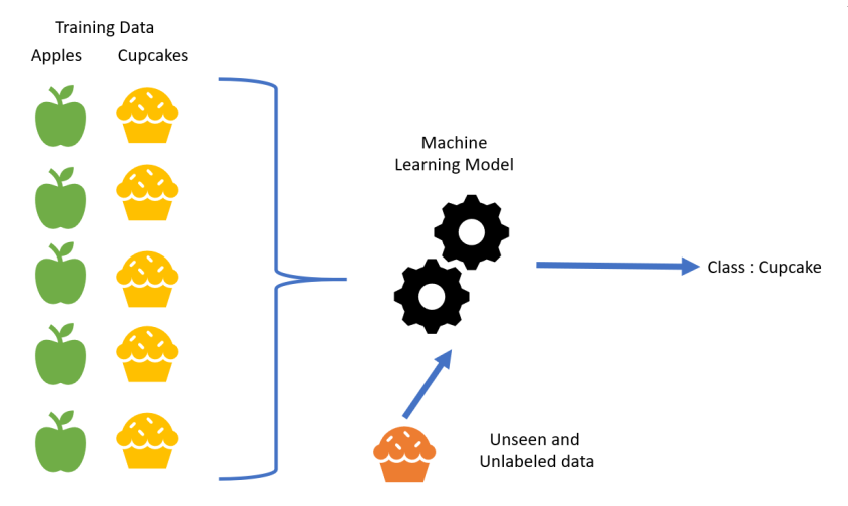
En apprentissage supervisé, un programme informatique reçoit un ensemble de données qui est étiqueté avec des valeurs de sorties correspondantes, ainsi on pourra alors « s’entrainer » sur ce modèle et une fonction sera déterminée. Cette fonction, ou algorithme pourra par la suite être utilisé sur de nouvelles données afin de prédire leurs valeurs de sorties correspondantes. C’est le cas par exemple de la Régression Linéaire, des Arbres de décisions, SVM (Support Vector Machine)…
En voici une illustration :
Pour l’Homme, il s’agit du même principe. De par son expérience, il va mémoriser une grande quantité d’informations et face à une situation, il va pouvoir se remémorer une situation similaire et émettre une conclusion.
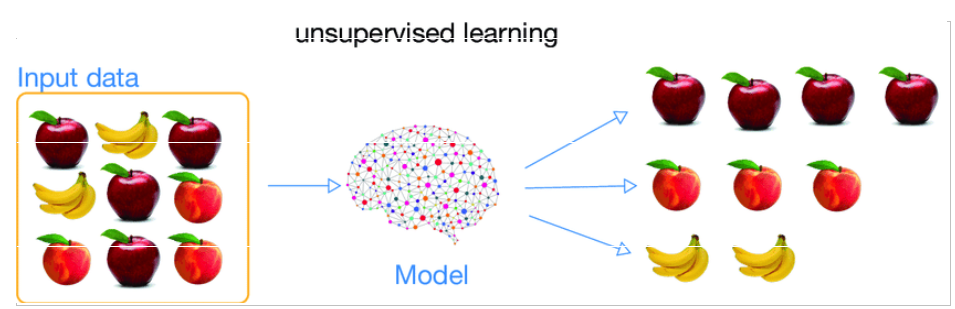
Dans l’apprentissage non-supervisé, l’ensemble des données n’a pas de valeurs de sorties spécifiques. Puisqu’il n’y a pas de bonnes réponses à tirer, l’objectif de l’algorithme est donc de trouver lui-même tous les modèles intéressants à partir des données. Certains des exemples bien connus d’apprentissage non supervisé comprennent les algorithmes de Clustering comme KMeans, DB-Scan et de réduction de dimension comme l’ACP (Analyse en Composantes Principales) et les réseaux de neurones.
Chez l’Homme, le principe est le même, certains critères vous nous permettre de différencier ce que se présente sous yeux et donc de déterminer différentes classes.
Dans l’apprentissage par renforcement, les « bonnes réponses » contiennent des récompenses, que l’algorithme doit maximiser en choisissant les actions à prendre.
Essentiellement, l’apprentissage par renforcement consiste à trouver le bon équilibre entre l’exploration et l’exploitation, ou l’exploration ouvre la possibilité de trouver des récompenses plus élevées, ou risque de n’obtenir aucunes récompenses. Les jeux tels que les Dames sont basés sur ce principe.
Le psychologue BF Skinner (1938), a observé le même résultat au cours d’une expérience sur les rats ou un levier offrait une récompense tandis qu’un autre administrait un choc. Le constat est simple, la punition a entrainé une diminution de la pression du levier de choc.
En comparant le Machine Learning à l’apprentissage d’un Humain, on observe donc beaucoup de similitude mais évidemment, il existe encore des différences fondamentales entre les deux :
Bien que les algorithmes d’apprentissage supervisé fournissent un aperçu complet de l’environnement, ils nécessitent une grande quantité de données pour que le modèle soit construit, ce qui peut être un peu lourd en termes de calculs.
A l’inverse, l’Homme a besoin de beaucoup moins de données pour être capable de faire des prédictions notamment en extrapolant les concepts qu’il a en mémoire. Le Machine Learning lui ne pourra pas le faire car les programmes n’interprètent pas des concepts mais des données.
Un autre problème survient quand on parle de sur-apprentissage ou « Overfitting » en anglais, qui se produit lorsque les données d’apprentissage utilisées pour construire un modèle expliquent très voire « trop » bien les données mais ne parviennent pas à faire des prédictions utiles pour de nouvelles données. L’Homme aura donc plus de flexibilité dans son raisonnement alors que les algorithmes de Machine Learning seront eux plus rigides.
En conclusion, le Machine Learning a souvent été comparé au raisonnement Humain, même si les deux ne sont pas exactement les mêmes.
Chez l’Homme, l’apprentissage a été façonné par des processus évolutifs pour devenir ce qu’il est aujourd’hui. Bien que de nombreuses théories ont tenté de d’expliquer ses mécanismes, sa nature dynamique conduit à dire que différentes stratégies peuvent être utilisées simultanément ou séparément, selon la situation. Il est donc difficile de le comparer au Machine Learning. Après tout, le Machine Learning a été programme par les humains… ainsi, de nouveaux concepts verront le jour pour pouvoir sans cesse améliorer nos algorithmes d’apprentissage qui sont déjà très efficace pour la prise de décision sur de large bases de données. Une Machine dotée d’une conscience ne verra sans doute jamais le jour, mais d’ici peu, la capacité de prise de décision des automates supplantera celle des humains dans quasiment tous les domaines