Pourquoi apprendre Python ? C’est l’une des premières questions que les étudiants se posent dans de nombreux centres académiques et formations Python. La réponse coule d’elle-même pour de nombreuses raisons. Python est un langage de programmation très populaire. Il a été une pièce maîtresse dans de grands projets et surtout dans l’introduction de pratiques innovantes lors de la programmation.
L’une des forces de ce langage de programmation est la large communauté de développeurs qui l’entoure. Tous ces professionnels cherchent à contribuer, partager et créer des logiciels évolutifs en communauté. En ce sens, il y a une sorte d’ambiance Python. Cela attire les programmeurs, les chercheurs et les professionnels de tous horizons qui cherchent à améliorer leurs performances de travail.
Python est un langage de programmation totalement gratuit et interprétatif qui est assez polyvalent. Il permet de mettre en place des projets variés allant du développement d’un site Web aux applications pour les systèmes d’exploitation.
La simplicité de la ligne de commande lors de la programmation est remarquable. C’est un fait connu de tous ceux qui l’utilisent. Et si vous n’êtes pas encore convaincu de suivre une formation Python, nous allons vous donner ici 5 raisons d’apprendre ce langage de programmation orienté objet.
Pourquoi suivre une formation Python ?
Python est un langage de programmation qui a beaucoup de qualité. C’est pour cette raison qu’il est actuellement très utilisé dans plusieurs domaines.
Open source
Si vous avez déjà programmé dans un autre langage, vous avez probablement remarqué qu’il s’agit de langages propriétaires avec quelques défauts dans la partie support. Et c’est encore pire pour les entreprises détenant des droits et faisant face par la suite à des problèmes juridiques.
Python est complètement open source. Il est accessible au public et tout le monde peut le modifier à sa guise en ajoutant ou en mettant de côté une partie du code toujours dans le but d’améliorer le travail de programmation.

En effet, Python a une licence connue sous le nom de PSFL ou Python Software Foundation License. Elle est compatible avec la licence publique générale GNU. De cette manière, il permet l’utilisation du code dans tout type de projet sans violations possibles du travail du programmeur et de ses actifs.
Multi-paradigme et multiplateforme
Initialement, Python a été conçu pour Unix. Mais, aujourd’hui, il peut fonctionner avec n’importe quel autre système. Il n’y a aucun risque qu’il y ait des problèmes d’implémentation tant que les utilisateurs recevront le Compiler approprié qui peut être configuré à partir du site officiel de Python.
Lorsqu’un langage est multi-paradigme, il permet non seulement de créer du développement Web, mais aussi de créer des applications ou des programmes sous d’autres critères de code structurel. Ainsi, Python est pratique pour développer des sous-paradigmes de programmation avancés contrairement à d’autres formes de programmation conventionnelles que l’on trouve notamment avec les langages plus anciens.
Python rassemble le meilleur de tous les langages en un seul. Il permet de développer des jeux, des applications, des sites Web et tout ce dont un programmeur est capable de faire, quelle que soit la complexité du projet.
C’est ainsi que les grandes entreprises utilisent Python au quotidien, notamment celles qui doivent interpréter des volumes massifs de données grâce à la data science et le Machine Learning.
Python est également présenté comme multiplateforme. En effet, il peut fonctionner sur n’importe quel système d’exploitation et a même été adapté à d’autres gadgets avec beaucoup de succès.
Polyvalence lors de la programmation
Avec Python, tout est possible. On peut créer n’importe quoi, du site Web à un programme ou une application pour effectuer une tâche telle que le calcul de valeurs statistiques ou la résolution de mathématiques complexes.
Syntaxe parfaite simple
La syntaxe Python est conviviale et cet élément met certainement en évidence la programmation. Pour les novices en programmation, il sera très facile d’effectuer le processus d’écriture du code.
Lorsqu’on parle de syntaxe, nous nous référons aux règles de protocole qui font partie d’un processus. D’une certaine manière, il s’agit des règles de grammaire et de style qui rendent un message lisible et compréhensible. On peut dire que le code est l’âme, mais la syntaxe donne forme à cette âme et lui donne le plus nécessaire pour avoir une certaine valeur.

En d’autres termes, la syntaxe de Python facilite fortement la formation à ce langage de programmation, d’où d’ailleurs cet engouement vers ce langage de programmation. Pour les personnes qui ne font que programmer, elle est très facile à comprendre par rapport à d’autres langages de programmation qui sont beaucoup plus compliqués.
Python rend la programmation beaucoup plus facile. Dans de nombreuses situations, lors d’un projet mené en équipe, c’est généralement la faiblesse des autres langages de programmation. Mais c’est tout le contraire avec Python, car le code est beaucoup plus compréhensible.
De quoi se compose une formation Python ?
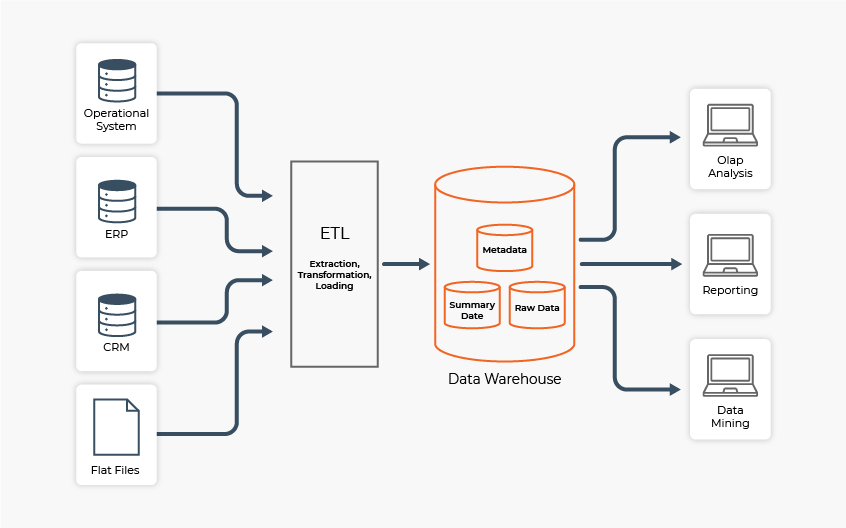
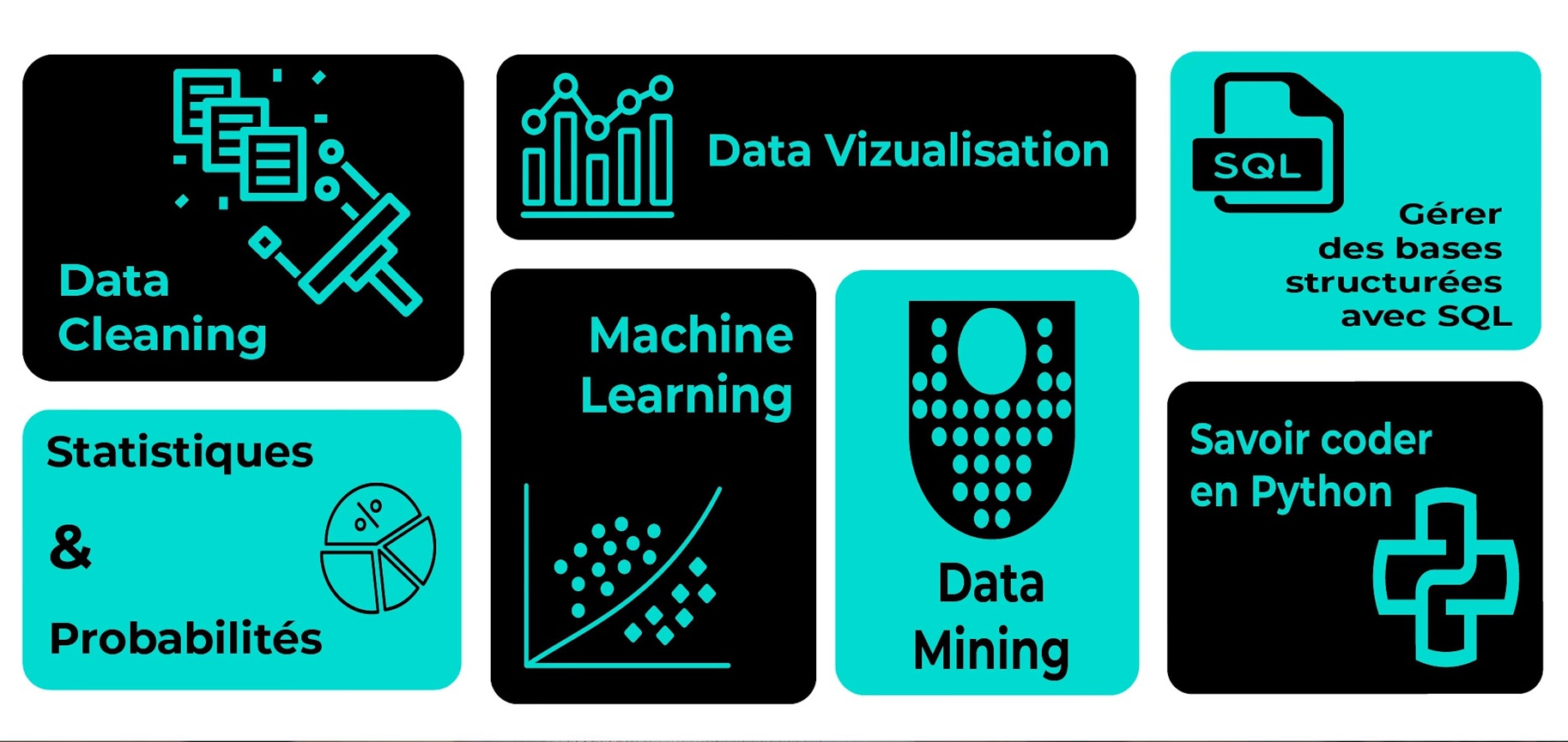
Une formation Python avec un programme et une qualité pédagogique similaire peut durer 12 mois au maximum. Elle nécessite bien évidemment des supports de cours, que ce soit une formation à distance, initiale ou en continue. Les sessions de formation peuvent comprendre plusieurs modules avec des exercices pratiques ou travaux pratiques en programmation Python (conception de base de données, création des applications avec des interfaces graphiques, développement web…), des pré-requis pour maîtriser ce langage de programmation. Mais avant tout, il faut savoir l’utiliser selon les deux modes de programmation proposés par Python.
Programmation structurée
Python a plusieurs paradigmes de programmation et l’un d’eux est la programmation structurée. Ce paradigme est basé sur 3 sous-programmes :
- La séquence qui se produit naturellement dans le langage. C’est l’ordre d’exécution dans lequel les instructions sont écrites.
- La sélection qui est l’exécution de phrases selon une condition.
- L’itération (cycle ou boucle) qui est l’exécution d’énoncés répétitifs ou non selon une condition vraie.
Programmation orientée objet
Le deuxième paradigme enseigné lors d’une formation Python est la programmation orientée objet, mais uniquement lorsque le premier paradigme est maitrisé. Ici, les étudiants apprennent à fusionner les deux paradigmes pour travailler avec des classes en Python. Ce paradigme est basé sur :
- L’héritage simple et multiple qui consiste à faire hériter à une classe enfant les méthodes et les attributs d’une classe parent.
- Le polymorphisme et l’encapsulation où le premier envoie les mêmes messages à différents objets et le second change l’état d’un objet uniquement à travers les opérations définies pour cet objet.
- La modularité qui consiste à subdiviser une application en modules indépendants.