Un Master Big Data peut signifier un débouché vers de nombreuses entreprises. Ces dernières ont en effet besoin de personnel professionnel pour gérer des données massives. Une formation en Big Data sert à obtenir des informations pertinentes permettant d’aider à la prise de décision. Et cela est essentiel dans la stratégie et la gestion de toute organisation, de la plus petite start up à la plus grande multinationale.
À grande échelle, le volume de données est énorme. Cela peut aller des transactions bancaires aux incidents de circulation en passant par les enregistrements des patients dans les hôpitaux, etc. Des milliards de données sont produites chaque seconde. En ce sens, une formation initiale ou continue dans le domaine du Big Data est l’un des pré-requis pour pouvoir travailler sur ces quantités colossales d’informations.
Quelques raisons de faire un Master Big Data
Il y a plusieurs raisons pour lesquelles il est tout à fait envisageable de se spécialiser dans le Big Data. En effet, un métier Big Data tel que le data analyst est un projet professionnel à la fois motivant et enrichissant.
Préparation aux défis
Le Master Big Data est intéressant pour la raison suivant : le professionnel se prépare à faire face à de nouveaux défis. Parmi ces derniers, on peut citer la vente, le Business Intelligence (BI), la gestion de bases de données, etc.
Vision globale
Le professionnel apprend à avoir une vision beaucoup plus globale de la nature des données. Sur cet aspect, il peut remarquer la différence dans leurs types et leur origine. Ainsi, il peut prendre une excellente décision lors de leur utilisation.
Développement des compétences techniques
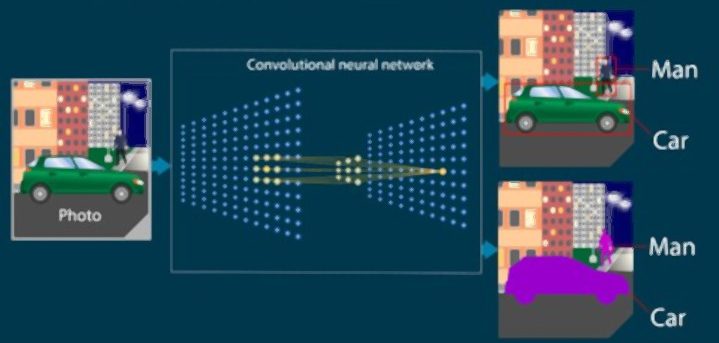
Dans le Big Data, il est important que le professionnel soit capable de développer différentes techniques. Celles-ci lui permettront de faire une analyse des données. Comme pour le cas des data scientists, le développement d’une Intelligence artificielle via la Machine Learning permet de construire des modèles prédictifs.

Utilisation d’outils
Un Master Big Data permet de savoir comment utiliser les différents outils nécessaires à l’analyse des données, à leur bonne segmentation, à la description du client, etc.
Forte demande
Actuellement, les entreprises ont une très forte demande pour les métiers du Big Data. Par conséquent, un Master Big Data est une excellente voie pour se former dans l’un des domaines du Big Data qui sont requis par les meilleures entreprises du monde.
De meilleures opportunités d’emploi
Le Big Data est actuellement l’un des sujets les plus évoqués sur le marché du travail. La recherche d’expériences professionnelles est en hausse en raison du salaire élevé. Par conséquent, suivre un cursus Master Big Data augmente les chances de postuler pour de meilleurs emplois.
Une meilleure préparation
Un Master Big data permet d’avoir un profil et un cursus beaucoup plus spécialisés qui sont plus intéressants pour les entreprises. De cette manière, les possibilités sont plus larges et importantes.
Les sujets traités tout au long d’un Master Big Data
Un cursus Master Big Data peut se composé de différents modules de formation. Leur nombre dépend de l’école ou de l’université qui le propose. À titre d’exemple, celui de l’Université Paris 8 est une formation continue sur plusieurs domaines. Par exemple, l’Intelligence artificielle, les systèmes d’information, le Big Data et l’apprentissage automatique.
Pour faire simple, un Master Big Data consiste avant tout à inculquer aux étudiants le contenu de la partie calcul ou traitement du Big Data : développement de l’infrastructure, du stockage et du traitement des données. Ensuite, il y a la partie analytique de la data science qui porte sur le traitement, le nettoyage et la compréhension des données ainsi que l’application algorithmique et la visualisation des données.
Une fois ces bases acquises, les étudiants passent vers la partie concernant le Business Intelligence en mettant l’accent sur la réception et l’application pratique des données. Bien évidemment, des matières optionnelles peuvent être ajoutées au cursus afin d’acquérir des compétences spécifiques comme la gestion de projet Big Data, le Cloud Computing ou le Deep Learning.
Les compétences développées durant un Master Big Data
- Programmation en R pour les méthodes statistiques et Python pour le Machine Learning.
- Utilisation des plateformes telles qu’AWS, BigML, Tableau Software, Hadoop, MongoDB.
- Gestion et récupération d’informations à l’aide de systèmes de gestion de bases de données relationnelles et NoSQL.
- Traitement des données distribué et application des modèles MapReduce et Spark.
- Configuration du framework Hadoop et utilisation des conteneurs.
- Visualisation des données et de reporting pour l’évaluation des modèles de classification et des processus métier.
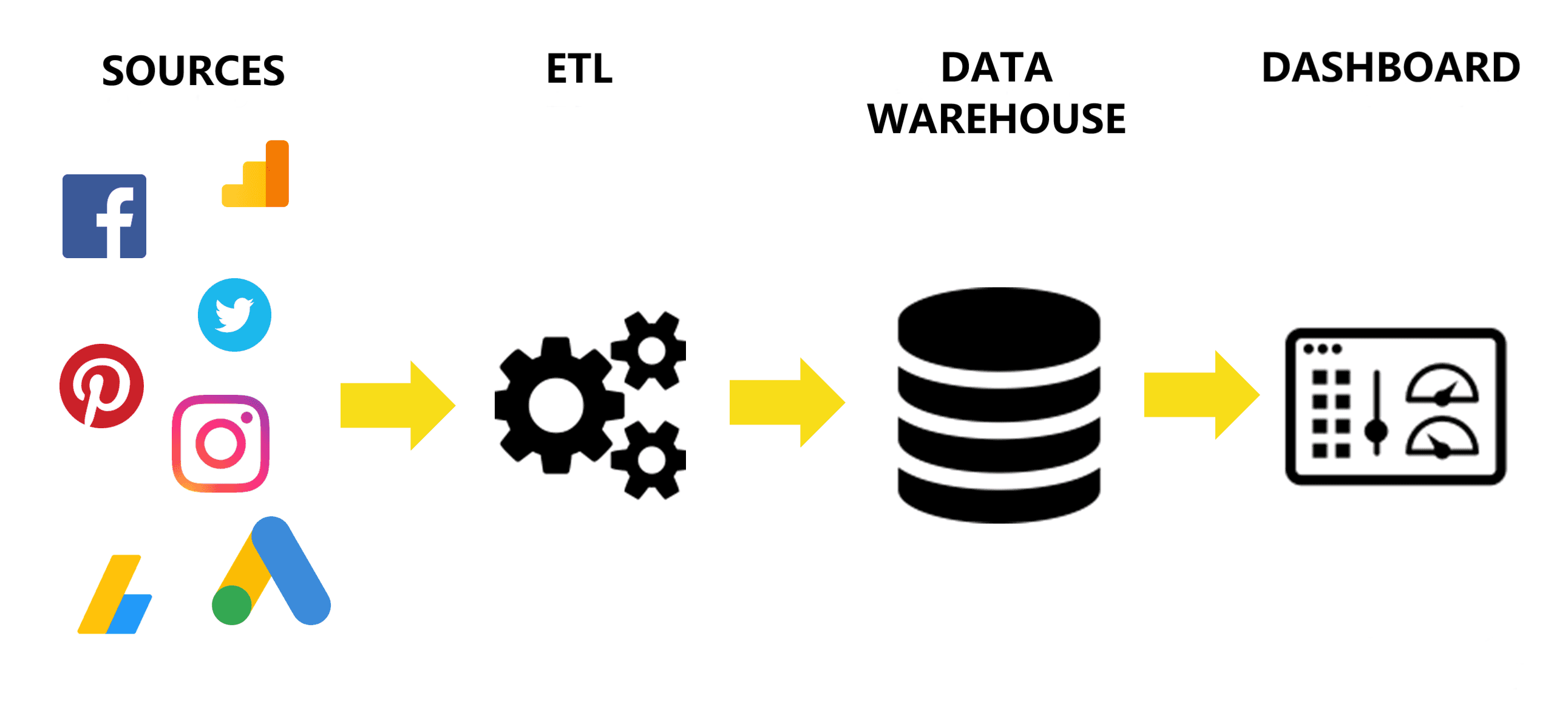
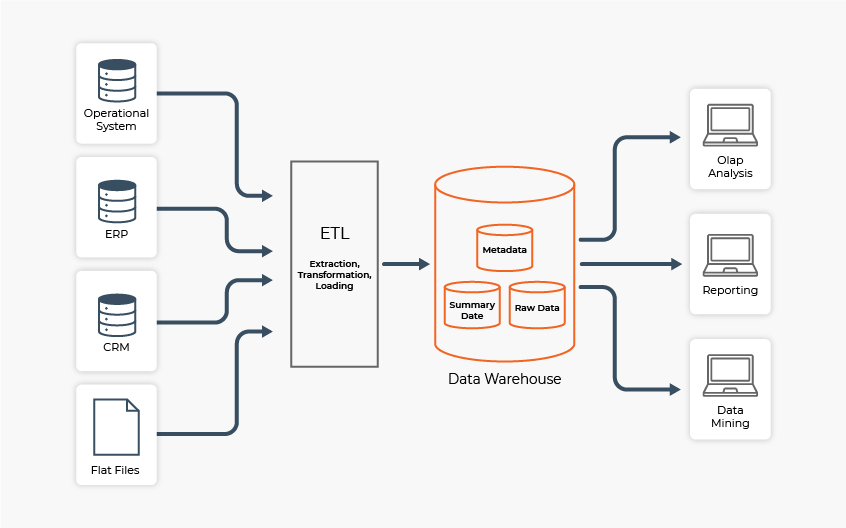
- Procédures ETL et utilisation appropriée des stratégies à l’aide d’outils de pointe.
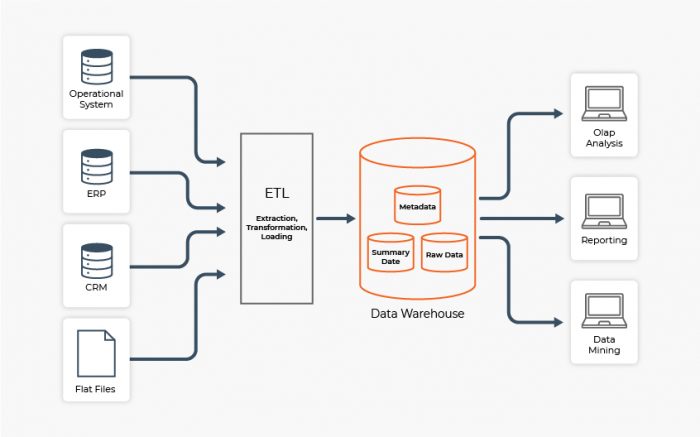
- Conception de stratégies de Business Intelligence et intégration du Big Data avec le Data Warehouse.
Les points forts d’un Master Big Data
Ceux qui souhaitent faire Master Big Data sont formés tout au long d’un cursus d’avant-garde. De plus, des mises à jour du contenu sont constamment enseignées en raison de l’évolution des technologies. Chaque étudiant acquière un profil professionnel qui répond aux besoins réels du marché.
En effet, le cursus comprend des phases pratiques. Ici, l’étudiant est formé aux nouvelles technologies liées au Big Data et aux outils les plus utilisés sur le marché du travail. Il travaille entre autre sur des projets pour développer et mettre en œuvre des solutions Big Data en situation réelle.
Par ailleurs, étant donné que des séminaires sur le domaine du Big Data sont souvent organisés, les étudiants en Master Big Data sont invités à y participer. Par exemple : des échanges avec des enseignants chercheurs, des chefs d’entreprise, etc. L’objectif est de compléter leurs connaissances des outils de Cloud Computing, Business Intelligence, Machine Learning, méthodologies de projet Big Data, etc.
Les débouchés avec un Master Big Data
Les professionnels du Big Data sont parmi les plus demandés par les entreprises. Ils seront également les plus recherchés à l’avenir. Les organisations se concentrent sur la collecte de données et l’analyse des informations clients ainsi que sur l’interprétation des données massives.
Le besoin de profils analytiques dans différents secteurs d’activité croît dans les entreprises. Par conséquent, elles requièrent plus d’analyse de données et de développement d’Intelligences Artificielles. C’est pour cette raison que les métiers du Big Data ci-dessous sont les postes en ligne de mire des détenteurs d’un Master Big Data.
1. Chief data officer
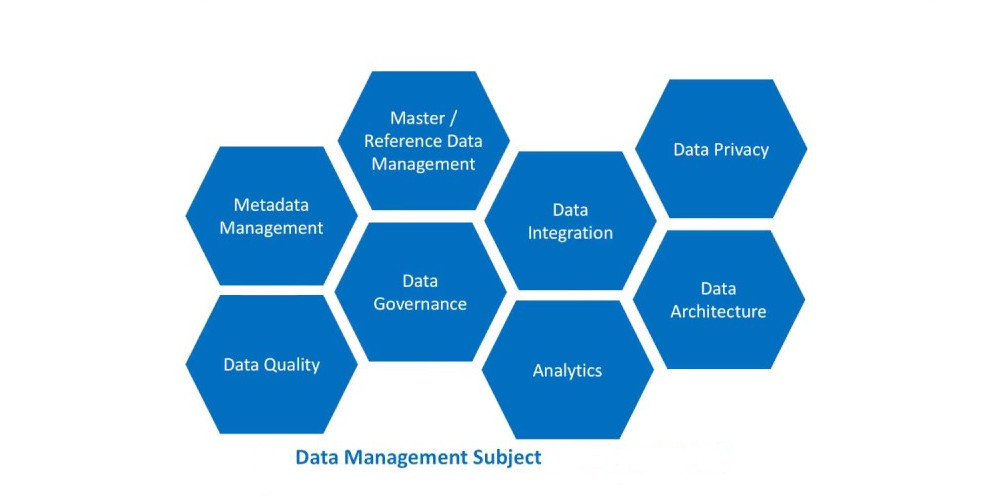
Le chief data officer (CDO) est le responsable des données au plus haut niveau sur le plan technologique, commercial et sécuritaire. Il est chargé de la gestion des données en tant qu’actif de l’entreprise. Ses fonctions comprennent la stratégie d’exploitation des données et la gouvernance des données.
2. Digital analyst
Sa mission est de donner du sens aux données collectées grâce à différents outils de mesure en ligne. À travers des rapports, des présentations et des tableaux de bord, il formule des recommandations stratégiques pour aligner les objectifs de l’entreprise sur ceux qu’il a pu mesurer en ligne. Il développe également des propositions d’optimisation pour les sites en ligne et conçoit des stratégies de mesure. Une connaissance approfondie du marketing, de la stratégie commerciale et des compétences en communication sont nécessaires pour qu’il ait la capacité de rendre compte des résultats.
3. Data analyst
Il vise à donner du sens aux données collectées à partir des projets d’intégration Big Data et transforme ces données en informations utiles et pertinentes pour l’entreprise. Il est en charge de la gestion et de l’infrastructure des données, de la gestion des connaissances et de la direction des plans d’analyse de données dans des environnements tels que les réseaux sociaux. Une connaissance de la programmation, des bibliothèques d’analyse de données, des outils d’Intelligence artificielle et des rapports est requise.
4. Data scientist
Le data scientist réalise des algorithmes d’apprentissage automatique qui seront capables d’automatiser les modèles prédictifs, c’est-à-dire, de prédire et de classer automatiquement les nouvelles informations. Pour ce faire, il possède des compétences en statistiques et mathématiques appliquées.
5. Data architect
Ce professionnel est en charge de la conception et de la gestion de gros volumes de données. Il prépare les bases de données d’une manière alignée sur les objectifs de l’entreprise. Ainsi, d’autres professionnels peuvent effectuer l’analyse des données pertinentes.
6. Business Intelligence analyst
Ce professionnel utilise des méthodes et des techniques analytiques pour comprendre le client et son impact sur l’entreprise. Il identifie les opportunités de monétisation grâce à l’analyse des données. Pour ce faire, il crée des stratégies centrées sur la relation client à partir de l’analyse des comportements issus du croisement des données CRM internes avec des données externes générées par l’interaction sociale. Cependant, il doit avoir un diplôme d’ingénieur, en statistiques ou en mathématiques ainsi que des compétences en gestion de bases de données et langages de programmation (ex : Python).
7. Expert en éthique et confidentialité des données
C’est l’un des profils qui sera demandé à l’avenir. En effet, il s’adaptera rapidement à tous les changements à venir dans un environnement très complexe et ambigu.