Le métier de data analyst est de plus en plus prisé sur le marché du travail. Toutes sortes d’entreprises recherchent ses compétences. Tout le monde parle du Big Data, de l’apprentissage automatique ou Machine Learning, du traitement de données, de la gestion de l’analyse de données et de l’exploration de données.
Dans cet article, nous allons apporter des explications sur le cœur de métier d’un analyste de données et tout ce qu’il apprend tout le long de la formation data analyst.
Le Big Data : centre de gravité de la formation data analyst
Bon nombre de jeunes diplômés se demandent encore pourquoi suivre une formation en Big Data. La réponse peut se résumer comme suit : parce que c’est ainsi qu’ils peuvent s’assurer d’avoir un emploi à l’avenir.
Beaucoup ne savent pas encore ce qu’est l’analyse de données. Pour résumer, il s’agit du moyen de rendre toutes les données acquises dans l’environnement numérique compréhensibles et utiles pour les entreprises à travers son analyse et sa gestion. Différents domaines de l’entreprise en bénéficie : marketing, commerce, relation client ou CRM, etc. Pour ce faire, le data analyst travaille avec des méthodologies de business intelligence et des outils logiciels spécifiques.
Que fait un data analyst ?
Il est important de connaître les principales fonctions d’un data analyst avant d’avoir un projet professionnel d’en devenir un.
1. Identification des données
La première chose qu’un data analyst fait avant d’analyser et de traiter les données est d’identifier les informations. Il s’agit uniquement des données qui intéressent l’entreprise depuis différentes sources. Pour ce faire, il doit structurer ou ordonner toutes ces données dans des graphiques et des tableaux pour en faire une présentation adéquate.

2. Établir des directives sur le comportement des clients
Une des principales fonctions du data analyst est de mettre en œuvre les stratégies nécessaires pour guider l’entreprise en fonction du comportement des clients. Les canaux numériques sont généralement les principaux domaines concernés. En effet, des actions plus personnalisées doivent être menées pour déterminer exactement ce que le public souhaite.
3. Traitement et regroupement des informations
L’analyste de données doit développer un traitement de données ardu à travers des opérations mathématiques et l’utilisation de langages de programmation. Il faut ensuite les regrouper par catégories d’informations pour les ordonner et en tirer des conclusions à forte valeur ajoutée pour l’entreprise.
4. Effectuer une communication transparente avec l’organisation
Travailler en tant que data analyst est en réalité devenir le gardien de toutes les informations traitées par l’entreprise. Son rôle est de générer des rapports. Ces derniers sont destinés aux services qui bénéficient des données analysées. Par conséquent, ils doivent être conforme au domaine d’activité de l’entreprise. D’une certaine manière, il interprète les données pour en tirer des informations utiles pour la prise de décision.
Pré requis pour suivre une formation data analyst
Pour devenir data analyst, il est nécessaire de répondre aux exigences essentielles répondant aux rigueurs du poste.
Niveau d’étude minimum
Devenir un data analyst n’est pas à la portée de quelqu’un ayant un niveau bac. Il faut au minimum avoir suivi une formation dans une école de marketing ou une école spécialisée dans le digital. Il existe toutefois plusieurs formations dispensées par des écoles d’informatique, des centres de formation et même par Pôle Emploi.
Par ailleurs, il n’est pas rare de voir l’analyse de données comme une spécialisation. C’est le cas notamment dans certains cursus pour l’obtention d’une Licence professionnelle, d’un Master ou d’un Master spécialisée.
Capacité de synthèse de données
Il est nécessaire d’avoir la capacité de synthétiser des données pour savoir comment choisir et extraire les informations les plus pertinentes et utiles pour l’entreprise. Il est très important de connaître ses objectifs au même titre que le secteur dans lequel elle opère. La détection des problèmes et leur résolution grâce à une analyse exhaustive de leurs caractéristiques fait ensuite appel à cette extraction de données.
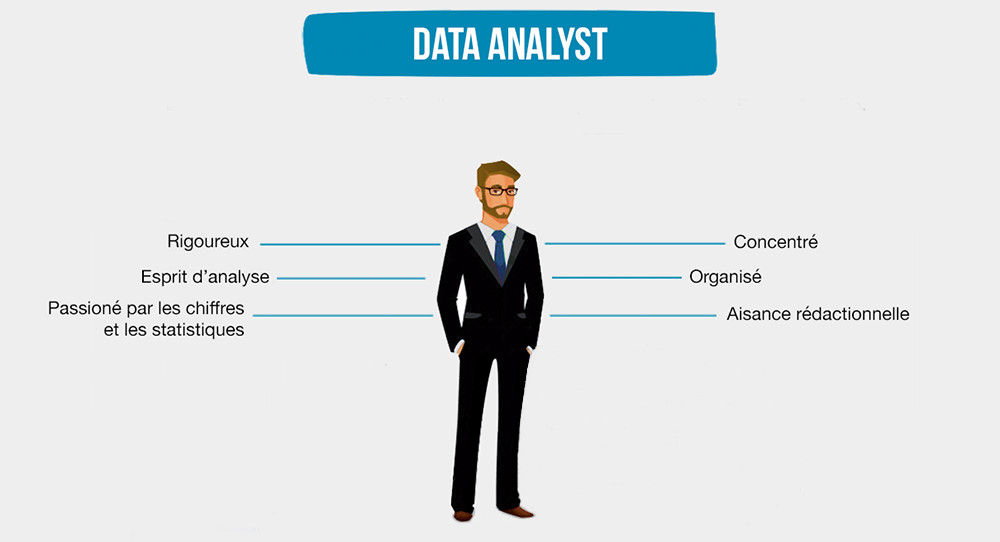
Communication fluide avec les parties prenantes
Il est nécessaire pour le data analyst d’avoir une communication fluide avec les dirigeants et les managers. Ce sont des pré-requis pour pouvoir expliquer les résultats de manière précise sans entrer dans les détails techniques. Un langage simple permettra à la direction de mieux comprendre la portée des conclusions de l’analyse.
Langage de programmation
Un data analyst doit avoir de bonnes compétences informatiques et savoir gérer les langages de programmation. En même temps, il doit maîtriser les mathématiques statistiques pour développer une analyse adéquate et tirer des conclusions d’un point de vue critique et objectif.
Transformer les données en recommandations est l’une des qualités les plus appréciées par les employeurs. C’est pour cela qu’ils décident d’inclure un data scientist et un data analyst parmi leur personnel.
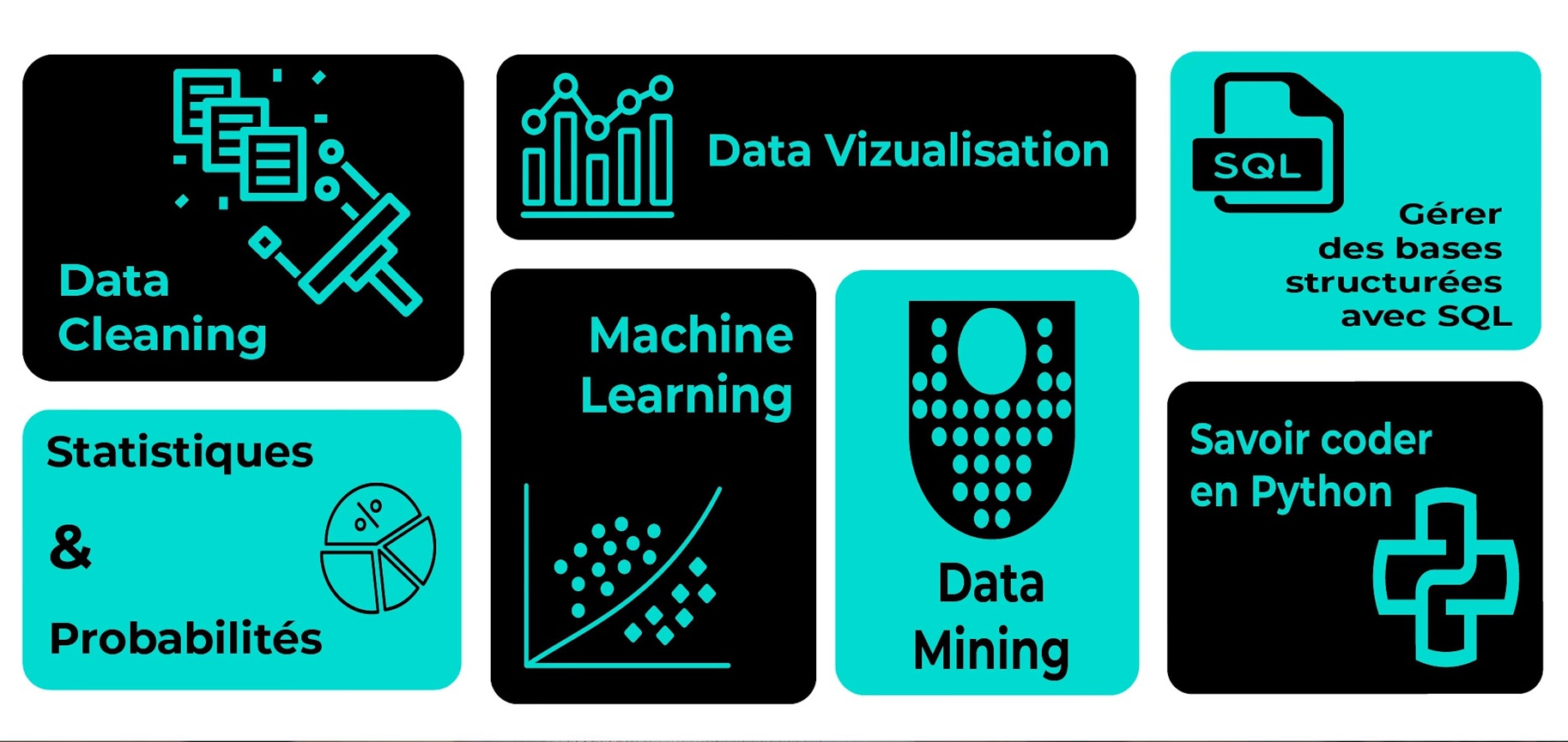
Qu’apprend-on d’une formation data analyst ?
On peut trouver facilement en ligne une formation data analyst . Que ce soit chez Pôle Emploi ou via une formation mise en place à distance, il existe de multiples sujets traités. Certains sont souvent abordés jusqu’à la fin de la formation :
- Fondamentaux du Big Data (techniques et concepts)
- Data science (comprendre la science des données)
- Comprendre le Big Data (analyse et visualisation des données)
- Comprendre l’analyse des données (Power BI)
- Business Intelligence (différence avec l’analyse de données)
- Langages de programmation (Python, R…)
- Techniques et outils de reporting essentiels
- Techniques outils et de reporting avancés
- Etc.